Reports.es
---
title: "Informes disponibles"
draft: false
# Algolia labels:
algolia:
ContentType: [
"User Guide"
]
---
Este documento enumera todos los tipos de informes estándar actualmente disponibles en Capacity Planner junto con su descripción y ejemplos. Cada informe incluye parámetros para añadir flexibilidad. Estos le permiten seleccionar y filtrar datos de interés y elegir formatos de salida. Para más detalles, consulte [Parámetros del informe](/reporting/report-param/).
Si requiere que se agregue un informe personalizado a su proyecto, por favor contacte a su representante de Capacity Planner.
## Instancias de AWS cambiadas
Este informe enumera todas las instancias EC2 que han cambiado de tipo de instancia dentro del marco de tiempo de la línea base seleccionada. La sección **Historic Values** del informe muestra los cambios de tipo de instancia, fechas efectivas y costes estimados bajo demanda. La sección **Current Values** muestra los valores actuales de las recomendaciones de ajuste de tamaño, ahorro de costes y valores de propiedades seleccionados a través del prompt **Grouping Values to Display**.
### Parámetros del informe
Below are the parameters used to configure this report. For information on parameters that are common across reports, such as entities or grouping filters, see [Report parameters](/reporting/report-param/).
* **Grouping Values to Display** — el informe permite la selección de múltiples propiedades de instancia para mostrar junto a las recomendaciones.
### Ejemplo
[//]: # (### Example)
In the image below, you can see an example of an output of this report.

## Informe de análisis de costes de AWS
Este informe le permite examinar lo que está sucediendo en su patrimonio en diferentes períodos de tiempo. Es una alternativa al timeburst para el análisis de costes diarios de lista.
El informe incluye la siguiente información:
* Puede desglosar la información por etiquetas.
* Puede ver cuándo las máquinas han estado inactivas, y cuánto le ha costado.
* Previsión basada en el gasto actual.
* La cantidad de dinero gastado para un producto específico en un día específico.
Para obtener más información sobre la configuración de recomendaciones de optimización de costes en la nube, consulte [Recomendaciones para entornos en la nube](/baseline-view/recommend/#configure-cloud-recommendations).

## Informe de cobertura de costes de AWS EC2 a lo largo del tiempo
Este informe proporciona una visión combinada completa de sus costes de funcionamiento de EC2 y una visión sobre cuán efectivos son los mecanismos de ahorro actuales.
En un entorno de AWS se muestran hasta cuatro series de tiempo:
* **Undiscounted costs** — esto representa los costes puros de su entorno de cómputo EC2 si no se aplicaran descuentos. Utiliza datos de referencia del proveedor sobre costes horarios de instancia.
* **Total current costs** — esta serie de tiempo representa los costes reales al considerar descuentos aplicados como resultado de inversiones en reservas y planes de ahorro (solo AWS). El área gris representa la cantidad de gasto en costes bajo demanda puros. Cualquier instancia no cubierta por reservas o planes de ahorro incurrirá en costes de referencia del proveedor (o costes personalizados basados en un Plan de Descuento Empresarial).
* **Savings Plans** — el área amarilla muestra la cantidad de costes que están cubiertos por planes de ahorro.
* **Reserved Instances** — el área azul muestra la cantidad de costes que están cubiertos por reservas.
### Ejemplo
[//]: # (### Example)
In the image below, you can see an example of an output of this report.
Este ejemplo muestra un entorno que ha estado ahorrando sustancialmente sobre los costes de pura demanda.
El 18 de mayo de 2021, la organización aumentó su inversión en Planes de Ahorro. Desde ese momento en adelante, no hay costes bajo demanda en absoluto. La combinación de reservas y planes de ahorro es tal que ninguna instancia está incurriendo en costes bajo demanda.
Es probable que la compra el 18 de mayo fuera mayor de lo requerido. Dado que no hay costes bajo demanda en absoluto desde ese punto en adelante, no hay más oportunidades para ahorros a corto plazo usando el ajuste de tamaño o apagando instancias inactivas. La razón de esto es que los costes de los planes de ahorro y reservas están comprometidos.
Recomendamos llevar a cabo el ajuste de tamaño y la gestión de máquinas inactivas. Esto ayudará a reducir los nuevos costes bajo demanda, optimizar las inversiones existentes y evitar la necesidad de comprar más planes de ahorro o reservas.

## Informe de periodicidad de instancia de AWS EC2
Este informe analiza la actividad de un grupo seleccionado de instancias y determina los intervalos de tiempo en los que esas instancias están inactivas de manera confiable durante el marco de tiempo seleccionado. La acción recomendada es que se pueda usar la automatización para encender y apagar las máquinas identificadas en estos tiempos para ahorrar costes en la nube.
Por defecto, el marco de tiempo seleccionado cubre toda la duración de la línea base, pero esto se puede configurar. Se recomienda ejecutar este informe durante el período más largo posible para garantizar la precisión.
### Parámetros del informe
Below are the parameters used to configure this report. For information on parameters that are common across reports, such as entities or grouping filters, see [Report parameters](/reporting/report-param/).
Los parámetros de configuración primarios son:
* **Idle CPU Threshold %** — el límite de CPU por debajo del cual la instancia puede considerarse inactiva.
* **Runtime % >=** — el tiempo mínimo que una instancia ha estado funcionando durante el rango de fechas elegido. Se recomienda no reducir esto del 90%.
* **Top ‘N’ Periods** — limita el informe a considerar los ‘N’ períodos de tiempo más valiosos. Aumentar esto aumentará el número de períodos de tiempo informados.
El período mínimo de tiempo considerado en este informe es una hora.
### Ejemplo
[//]: # (### Example)
In the image below, you can see an example of an output of this report.
Este ejemplo muestra que un domingo, entre las 3:00 a.m. y las 7:59 p.m., 6 máquinas están inactivas de manera confiable. Es decir, son instancias de larga duración y han estado constantemente por debajo del 5% de utilización de CPU durante esos tiempos.

Este informe proporciona la siguiente información:
* El tipo de periodicidad identificada puede ser Diaria o Horaria:
+ Diaria indica que las máquinas resaltadas en esta fila demuestran periodicidad confiable para todo el día. Esto indicaría que estas máquinas estuvieron inactivas de manera confiable durante todo un día.
+ Cualquier máquina resaltada en la fila horaria son aquellas que demuestran inactividades periódicas confiables en esa ventana de tiempo.
* **Start Time** — indica el inicio de la ventana de tiempo de inactividades periódicas confiables.
* **End Time** — indica el fin de la ventana de tiempo de inactividades periódicas confiables.
* **Cost** — el gasto bajo demanda de las instancias identificadas durante esa ventana de tiempo.
* **Instances** — el número de máquinas inactivas durante esa ventana de tiempo.
* **Total Cost** — el gasto total bajo demanda de máquinas funcionando cuando están inactivas.
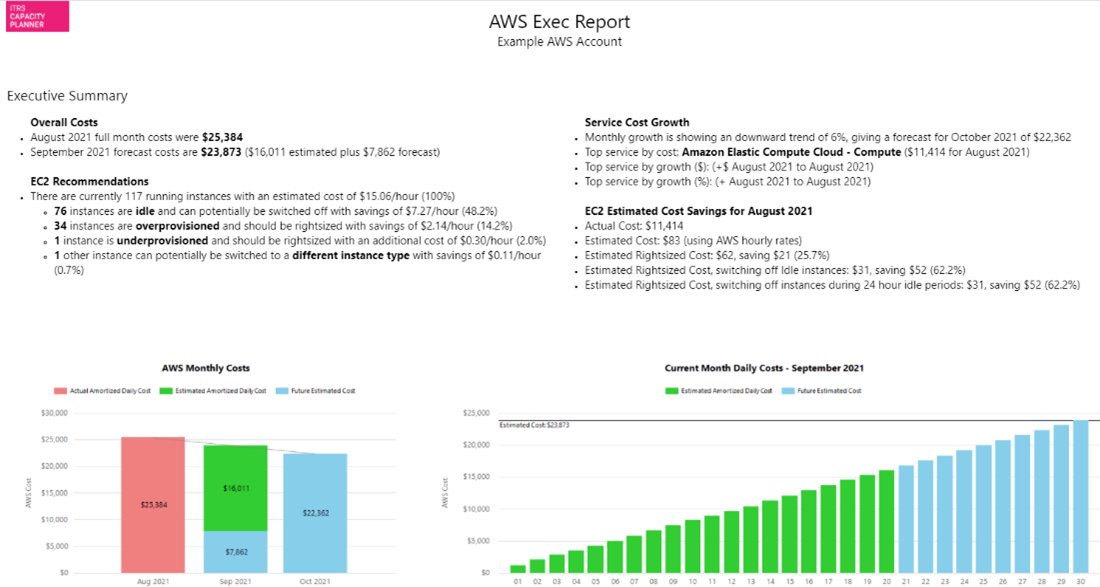
Informe ejecutivo de AWS Copied
Este informe muestra un resumen de costes y tendencias de costes, crecimiento del servicio, recomendaciones de instancias y posibles ahorros.
Parámetros del informe Copied
A continuación, se presentan los parámetros utilizados para configurar este informe. Para obtener información sobre parámetros que son comunes en todos los informes, como entidades o filtros de agrupación, consulte Parámetros del informe.
- AWS account — seleccione cuál de sus cuentas de AWS debe incluirse en el informe.
- Daily cost metric — permite la selección de métrica de coste, por ejemplo, Amortizado o Mezclado.
- Previous months to include — indique cuántos meses desea incluir en el informe.
- VM grouping — seleccione qué agrupaciones de VM utilizar en el informe.
Para obtener más información sobre la configuración de recomendaciones de optimización de costes en la nube, consulte Recomendaciones para entornos en la nube.
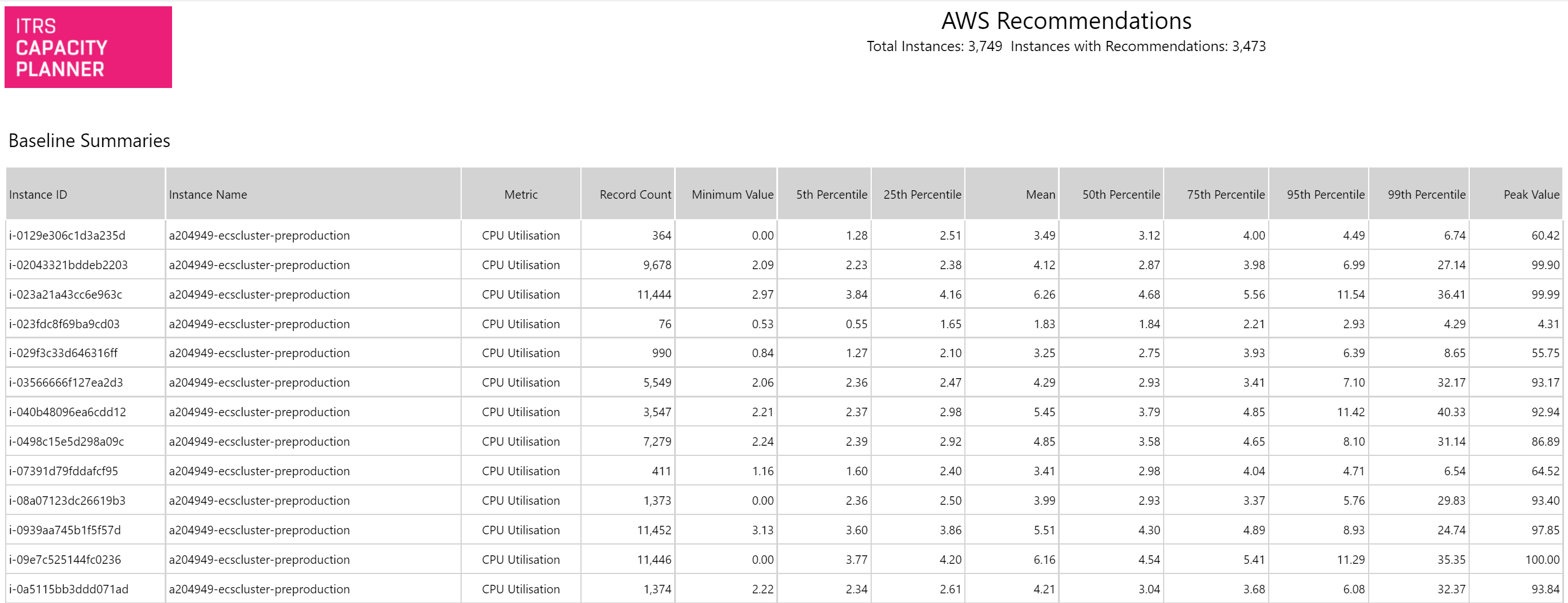
Recomendaciones de AWS Copied
Este informe muestra una lista de instancias de EC2 con recomendaciones de redimensionamiento en todo su entorno junto con los posibles ahorros basados en estas recomendaciones. Solo se muestran las instancias donde se recomienda un cambio (por ejemplo, de tipo de instancia o ubicación).
Para obtener más información sobre cómo configurar recomendaciones, consulte Configurar recomendaciones en la nube.
Parámetros del informe Copied
Below are the parameters used to configure this report. For information on parameters that are common across reports, such as entities or grouping filters, see Report parameters.
- AWS account — seleccione cuál de sus cuentas de AWS debe incluirse en el informe.
- Report Sections to Include — este informe se divide en tres secciones: Recomendaciones, resúmenes de línea base y gráficos de caja diarios. Puede decidir qué secciones mostrar.
Tenga en cuenta que si selecciona más de una sección, se muestran una tras otra, por lo que dependiendo de cuántos datos muestre su informe, es posible que tenga que avanzar por las páginas del informe para ver la siguiente sección. Cuando se exporta a Excel, las tres secciones se muestran en hojas de cálculo separadas.
- State — permite filtrar instancias por estado de VM.
- Include all idle instances — las instancias inactivas con recomendaciones de redimensionamiento siempre se incluyen por defecto. Seleccione esta opción para también incluir todas las demás instancias inactivas, permitiéndole ver los posibles ahorros si estas se apagan.
- Exclude ignore list instances — puede incluir o excluir todas las instancias que haya agregado a la lista de ignorados. Para más información, consulte Instancias ignoradas.
Ejemplo Copied
In the image below, you can see an example of an output of this report.
El orden predeterminado puede cambiarse haciendo clic en las flechas sobre cada columna para ordenar por esa columna.
Instancias cambiadas de Azure Copied
Este informe lista todas las VMs de Azure que han cambiado de tipo de VM dentro del marco temporal de la línea base seleccionada. La sección Historic Values del informe muestra los cambios de tipo de VM, las fechas efectivas y los costes estimados bajo demanda. La sección Current Values muestra los valores actuales de recomendaciones de redimensionamiento, ahorro de costes y valores de propiedades seleccionados a través del prompt Grouping Values to Display.
Parámetros del informe Copied
Below are the parameters used to configure this report. For information on parameters that are common across reports, such as entities or grouping filters, see Report parameters.
- Grouping Values to Display — el informe permite la selección de múltiples propiedades de VM para mostrar junto con las recomendaciones.
Informe ejecutivo de Azure Copied
Este informe muestra un resumen de costes y tendencias de costes, crecimiento del servicio, recomendaciones de instancias y posibles ahorros.
Parámetros del informe Copied
Below are the parameters used to configure this report. For information on parameters that are common across reports, such as entities or grouping filters, see Report parameters.
- Azure subscription — seleccione cuál de sus suscripciones de Azure debe incluirse en el informe.
- Daily cost metric — permite la selección de métrica de coste, por ejemplo, Amortizado o Mezclado.
- Previous months to include — indique el número de meses que desea incluir en el informe.
- VM grouping — seleccione qué agrupaciones de VM utilizar en el informe.
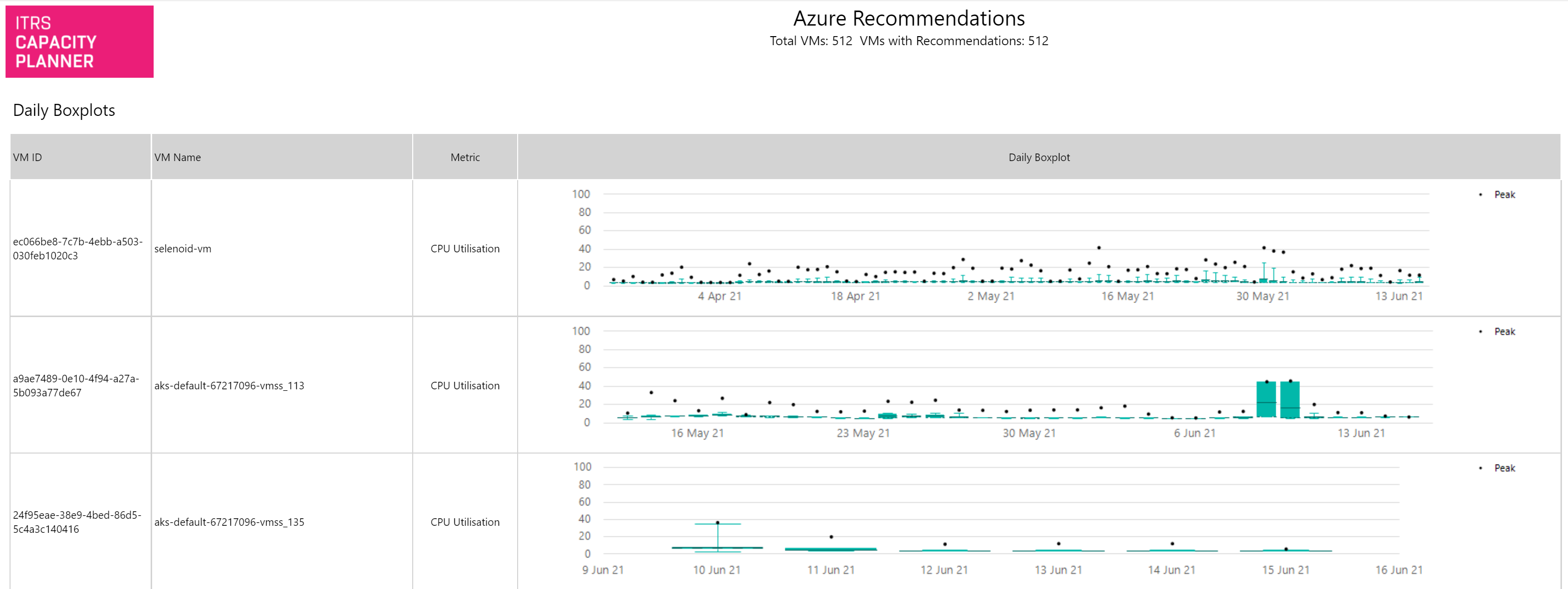
Recomendaciones de Azure Copied
Este informe muestra una lista de VMs de Azure con recomendaciones de redimensionamiento en todo su entorno junto con los posibles ahorros basados en estas recomendaciones. Solo se muestran las VMs donde se recomienda un cambio.
Para obtener más información sobre cómo configurar recomendaciones, consulte Configurar recomendaciones en la nube.
Parámetros del informe Copied
A continuación, se presentan los parámetros utilizados para configurar este informe. Para obtener información sobre parámetros que son comunes en todos los informes, como entidades o filtros de agrupación, consulte Parámetros del informe.
- Azure subscription — seleccione cuál de sus suscripciones de Azure debe incluirse en el informe.
- Report Sections to Include — este informe se divide en tres secciones: Recomendaciones, resúmenes de línea base y gráficos de caja diarios. Puede decidir qué secciones mostrar.
Tenga en cuenta que si selecciona más de una sección, se muestran una tras otra, por lo que dependiendo de cuántos datos muestre su informe, es posible que tenga que avanzar por las páginas del informe para ver la siguiente sección. Cuando se exporta a Excel, las tres secciones se muestran en hojas de cálculo separadas.
- Powerstate — permite filtrar instancias por el estado de energía de Azure.
- Include all idle instances — las instancias inactivas con recomendaciones de redimensionamiento siempre se incluyen por defecto. Seleccione esta opción para también incluir todas las demás instancias inactivas, permitiéndole ver los posibles ahorros si estas se apagan.
- Exclude ignore list instances — puede incluir o excluir todas las VMs que haya agregado a la lista de ignorados. Para más información, consulte Instancias ignoradas.
Ejemplo Copied
In the image below, you can see an example of an output of this report.
La ordenación predeterminada se puede cambiar haciendo clic en las flechas sobre cada columna para ordenar por esa columna.
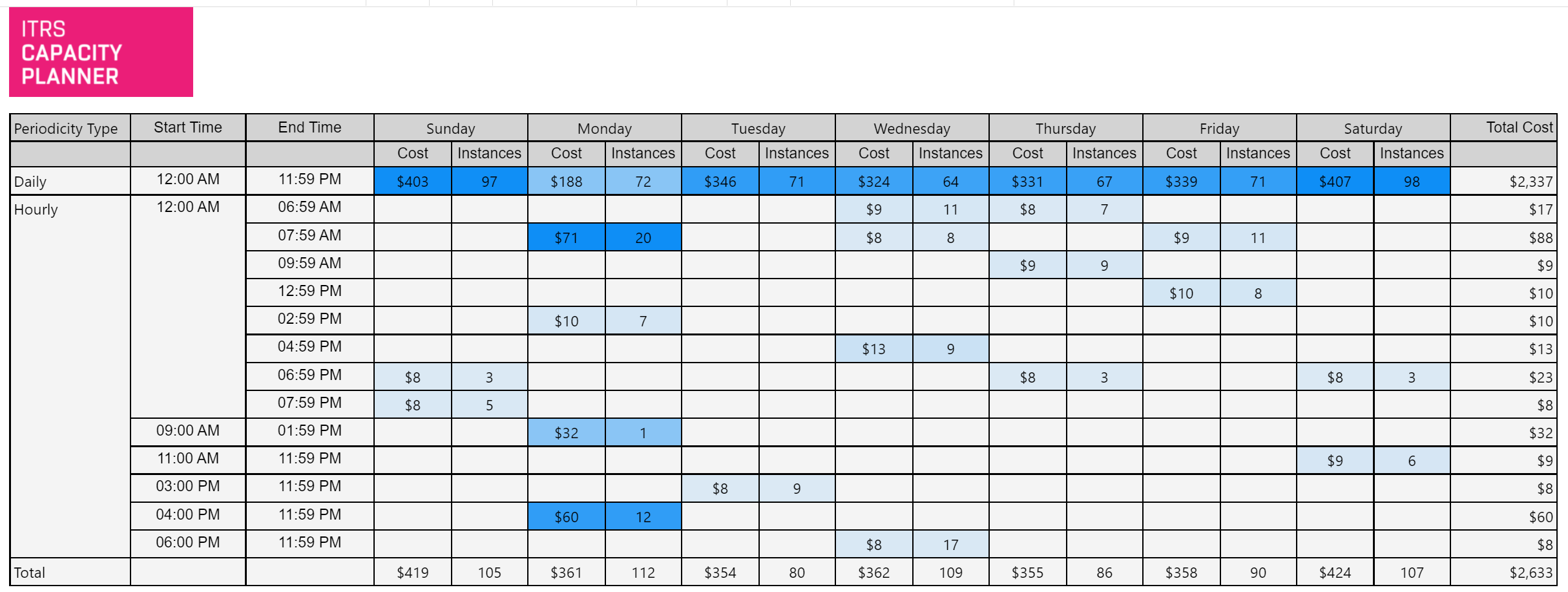
Periodicidad de VM de Azure Copied
Este informe identifica períodos regulares de inactividad de las VM de Azure en una base diaria y semanal e indica los ahorros potenciales que se podrían realizar si las VM se detienen durante los períodos indicados.
Parámetros del informe Copied
Below are the parameters used to configure this report. For information on parameters that are common across reports, such as entities or grouping filters, see Report parameters.
- Idle CPU Threshold % — el límite de CPU por debajo del cual se puede considerar que la máquina está inactiva.
- Runtime % >= — el tiempo mínimo que una máquina ha estado funcionando durante el rango de fechas elegido. Se recomienda no reducir esto del 90%.
- Top ‘N’ Periods — limita el informe para considerar los ‘N’ períodos de tiempo más valiosos. Aumentar esto aumentará el número de períodos de tiempo informados.
Ejemplo Copied
In the image below, you can see an example of an output of this report.
Eventos de clúster Copied
Este informe muestra todos los eventos de capacidad de clúster proyectados actualmente y la serie temporal de estos eventos. También proporciona información sobre con qué frecuencia se ha planteado este evento de clúster y en qué nivel de gravedad. Puede ver el historial de cada evento utilizando la opción Drill through to Event History que lo lleva al informe Historial de eventos de clúster.
Ejemplo Copied
In the image below, you can see an example of an output of this report.
Este ejemplo muestra un aumento de la CPU con el tiempo. Si esta tendencia continúa, el clúster pronto tendrá menos de un servidor redundante disponible.

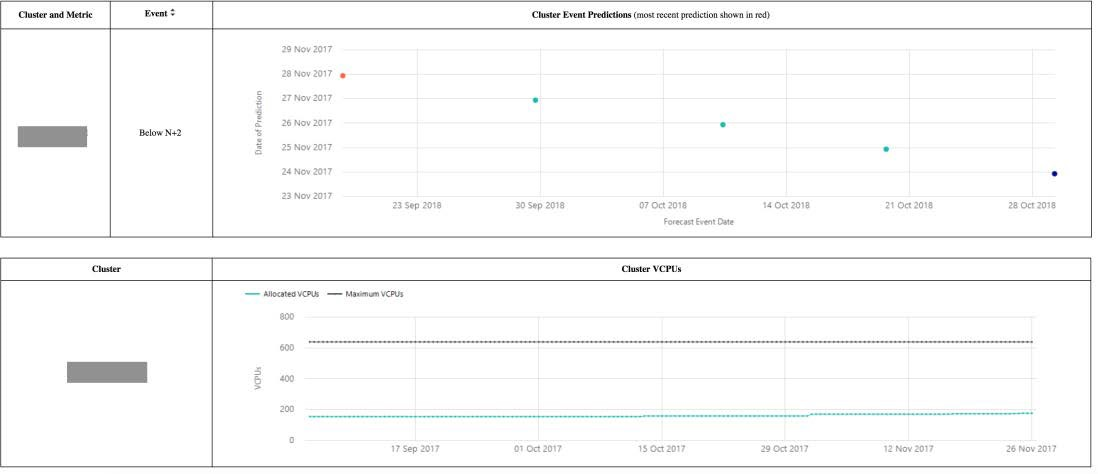
Historial de eventos de clúster Copied
Este informe muestra el historial de eventos para cada clúster:
- Un indicador azul marca la fecha de saturación esperada cuando se planteó el evento por primera vez.
- Un indicador rojo marca la fecha de saturación calculada más recientemente.
- Una serie de indicadores muestran cada fecha entre la primera y la más reciente fecha de saturación.
Esto se puede utilizar para obtener una comprensión de si un evento se está acercando y es más inminente, o se está moviendo más hacia el futuro como resultado de una tendencia a aplanarse.
También se proporciona un gráfico que muestra la serie temporal de vCPUs asignadas en el clúster, dando una indicación del crecimiento que también puede contribuir a los cambios en las fechas de saturación del clúster.
Ejemplo Copied
In the image below, you can see an example of an output of this report.
Este ejemplo muestra un evento de clúster que se ha planteado varias veces. Cuando se planteó por primera vez, la fecha de saturación proyectada era el 29 de octubre de 2018. La fecha de saturación más reciente pronosticada es ahora el 18 de septiembre, como indica el indicador rojo en el gráfico.
El gráfico inferior muestra una tendencia de la serie temporal de vCPUs asignadas en este clúster. Ha habido un aumento durante los últimos 3 meses que probablemente está llevando al cambio en la fecha de saturación proyectada para el clúster.
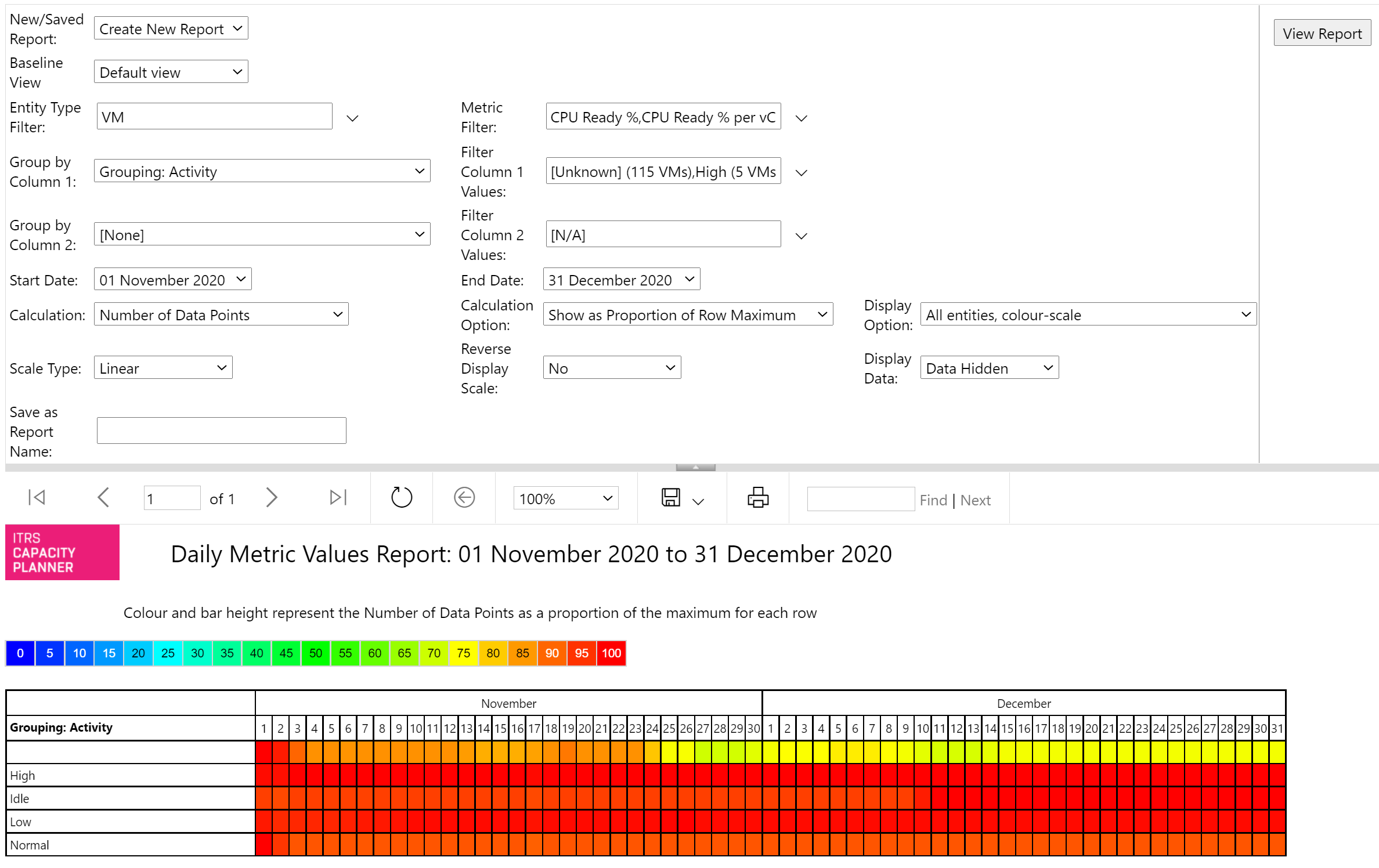
Valores métricos diarios Copied
Este informe muestra un mapa de calor de la cobertura de datos diarios o valores métricos diarios para un rango de fechas específico y un conjunto de métricas.
Parámetros del informe Copied
Below are the parameters used to configure this report. For information on parameters that are common across reports, such as entities or grouping filters, see Report parameters.
- Entity type filter — el informe se puede ejecutar en uno o más de los tipos de entidad disponibles.
- Metric filter — permite la selección de una o más métricas.
- Group by column — los datos se pueden agrupar por tipo de entidad, nombre de entidad, nombre de métrica o valor de propiedad.
- Filter column values — si los datos se agrupan por valor de propiedad, se puede agregar un filtro al informe restringiendo los valores enumerados.
- Start date / End date — permite la selección del rango de fechas a incluir en el informe.
- Calculation — el mapa de calor puede representar el número de puntos de datos, número de entidades suministrando datos o un percentil de valor métrico diario.
- Calculation option — la escala de color o escala de grises de cada celda puede representar una proporción del valor máximo de la fila o proporción del valor del informe.
- Display option — el mapa de calor se puede mostrar en color o como una escala de grises. Además, las entidades se pueden restringir solo a aquellas con cobertura completa de datos del rango de fechas seleccionado.
- Scale type — se puede elegir entre escala lineal y logarítmica.
- Reverse display scale — esta opción invierte la escala de color o escala de grises.
- Display data — los valores de datos en cada celda se pueden mostrar u ocultar.
Ejemplo Copied
In the image below, you can see an example of an output of this report.
Cobertura de datos Copied
Este informe le permite monitorear el volumen de datos recibidos cada día por Capacity Planner a través de diferentes tipos de entidad y métricas.
Puede seleccionar uno o más tipos de entidad y una o más métricas como mínimo. Los resultados se pueden mostrar en diferentes niveles de resumen, con la capacidad de agrupar los resultados por lo siguiente:
- Tipo de entidad
- Nombre de entidad
- Nombre de métrica
- Valores de agrupación
Parámetros del informe Copied
Below are the parameters used to configure this report. For information on parameters that are common across reports, such as entities or grouping filters, see Report parameters.
La cobertura se muestra en un informe de matriz diaria, con las siguientes opciones disponibles:
- Cálculo — el informe puede mostrar ya sea el número de puntos de datos recibidos para cada día o el número de entidades suministrando datos para un rango de fechas seleccionado que usted ha seleccionado.
- Opción de visualización:
- El informe puede mostrar ya sea todas las entidades o entidades con cobertura incompleta. La cobertura incompleta significa que Capacity Planner recibió menos puntos de datos de los esperados, o que hay brechas en los datos debido a un problema en el sistema.
- Puede seleccionar entre color completo y escala de grises.
- Opción de cálculo — como una proporción del máximo de la fila o como una proporción del máximo del informe.
- Tipo de escala — puede ser lineal o logarítmico.
- Mostrar Datos — puede mostrar u ocultar datos detallados del informe. Si solo le interesa observar las variaciones de color en lugar de los números absolutos, seleccione Data Hidden.
Ejemplo Copied
In the image below, you can see an example of an output of this report.

Análisis de métricas — gráficos múltiples Copied
Este informe le permite crear diagramas de caja, gráficos de barras, gráficos de líneas y gráficos radar, así como gráficos de tendencia lineal y gráficos de dispersión con cálculos de regresión lineal. El informe se puede ejecutar utilizando una o varias métricas en grupos de entidades en cualquier nivel de agregación disponible dentro de Capacity Planner.
Muestra un gráfico separado para cada serie temporal en el informe. Si desea mostrar todas las entidades en el mismo gráfico, utilice el Análisis de métricas — gráfico único.
Una característica adicional le permite ingresar sus propios valores de umbral RAG (Rojo, Ámbar, Verde) y mostrarlos y ordenarlos por ellos. Si no se seleccionan operadores de umbral, la columna de estado RAG se oculta y las líneas de umbral RAG y la columna de estado no aparecen en el informe.
El Linear Trend y Scatter Plots calculan líneas de regresión lineal y los valores asociados de intersección, gradiente y R2. Los informes se pueden filtrar y ordenar por valores R2 para permitir la identificación de los más significativos. En estos informes, los valores de umbral rojo y ámbar se utilizan para calcular valores en la línea de ajuste óptimo permitiendo mostrar fechas y valores proyectados. Por ejemplo, en el informe de Tendencia Lineal, la visualización del informe muestra las fechas proyectadas en las que se alcanzarían los valores de umbral ámbar y rojo.
Tipos de gráficos disponibles son:
- Box plot — este gráfico se puede utilizar para resúmenes diarios y superiores (día, semana, mes, etc.). Muestra valores percentiles como una caja con bigotes arriba y abajo para indicar el rango de distribución de valores. Este es el único tipo de gráfico que puede mostrar más de un valor percentil. Sin embargo, el selector Percentil/Valor todavía controla la métrica utilizada para los umbrales RAG.
- Bar chart — los valores se muestran como barras verticales.
- Line chart — los valores se trazan como puntos en una línea.
- Linear trend — este gráfico traza los valores de las métricas y la línea de regresión lineal para cualquier métrica dada. Este gráfico se debe usar con datos promedio por hora o sin agregar para tendencias a corto plazo. Las tendencias a largo plazo pueden hacer uso de valores de resumen diarios.
- Radar chart — este gráfico traza todas las entidades en una visualización radar única. Este gráfico funciona bien para comparar métricas pero recomendamos usarlo con un número relativamente pequeño de entidades para mejorar la legibilidad.
- Scatter plot (metric pairs) y scatter plot (metric pairs reversed) — estos tipos de gráfico aparecen en la lista desplegable si se seleccionan dos métricas. Calculan líneas de regresión lineal basadas en valores de pares de métricas. Cambiar entre estos dos tipos de informes invierte los ejes X e Y del informe. Los valores de umbral Rojo y Ámbar calculan valores del eje X a partir de los valores dados del eje Y basados en la línea de regresión.
- Stacked bar chart — este gráfico presenta una sola barra por fecha mostrando los valores métricos relativos.
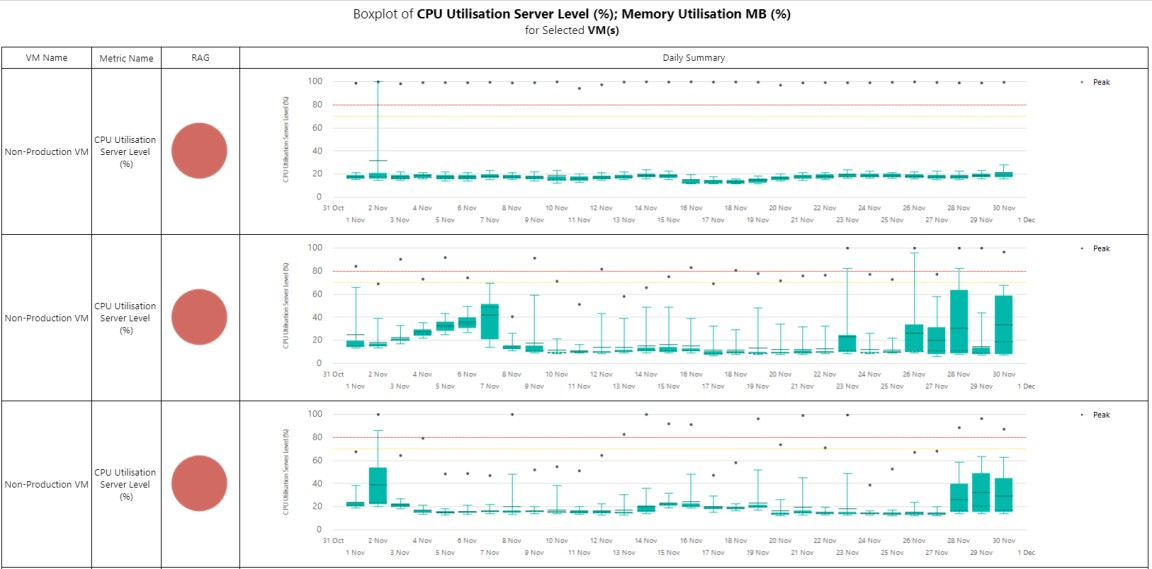
Ejemplo Copied
In the image below, you can see an example of an output of this report. Muestra diagramas de caja diarios de CPU y memoria con el umbral RAG rojo establecido en el 80% y el umbral ámbar establecido en el 70%. El informe está ordenado por estado RAG.
Análisis de métricas — gráfico único Copied
Este informe le permite crear gráficos de barras, diagramas de caja, gráficos de líneas y mapas de árbol con una o más entidades mostradas en el mismo gráfico. Trazar múltiples entidades en el mismo gráfico puede permitir comparaciones más fáciles lado a lado.
Si desea mostrar cada entidad en un gráfico separado, utilice el Análisis de métricas — gráficos múltiples.
Los tipos de gráficos disponibles son:
- Bar chart — los valores se representan como barras horizontales. Los nombres de las entidades, fechas y valores se pueden ordenar en el gráfico utilizando el indicador de orden
 .
. - Box plot — este gráfico se puede utilizar para resúmenes diarios y superiores (día, semana, mes, etc.). Muestra valores percentiles como una caja con bigotes arriba y abajo para indicar el rango de distribución de valores. Este es el único tipo de gráfico que puede mostrar más de un valor percentil. Sin embargo, el selector Percentil/Valor todavía controla la métrica utilizada para los umbrales RAG.
- Line chart — los valores se trazan como puntos en una línea.
- Treemap — las entidades se muestran como áreas en un rectángulo, con el tamaño del área representando el valor.
Ejemplo Copied
En las imágenes a continuación, puede ver ejemplos de gráficos de líneas, diagramas de caja y gráficos de barras para este informe.
Informe de gráfico de líneas:
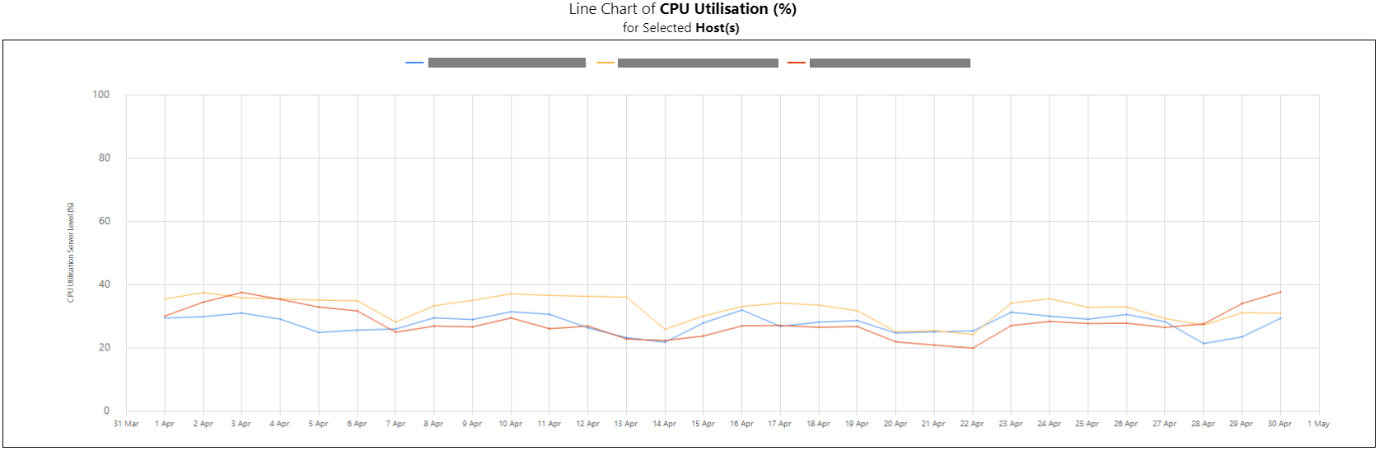
Informe de diagramas de caja:
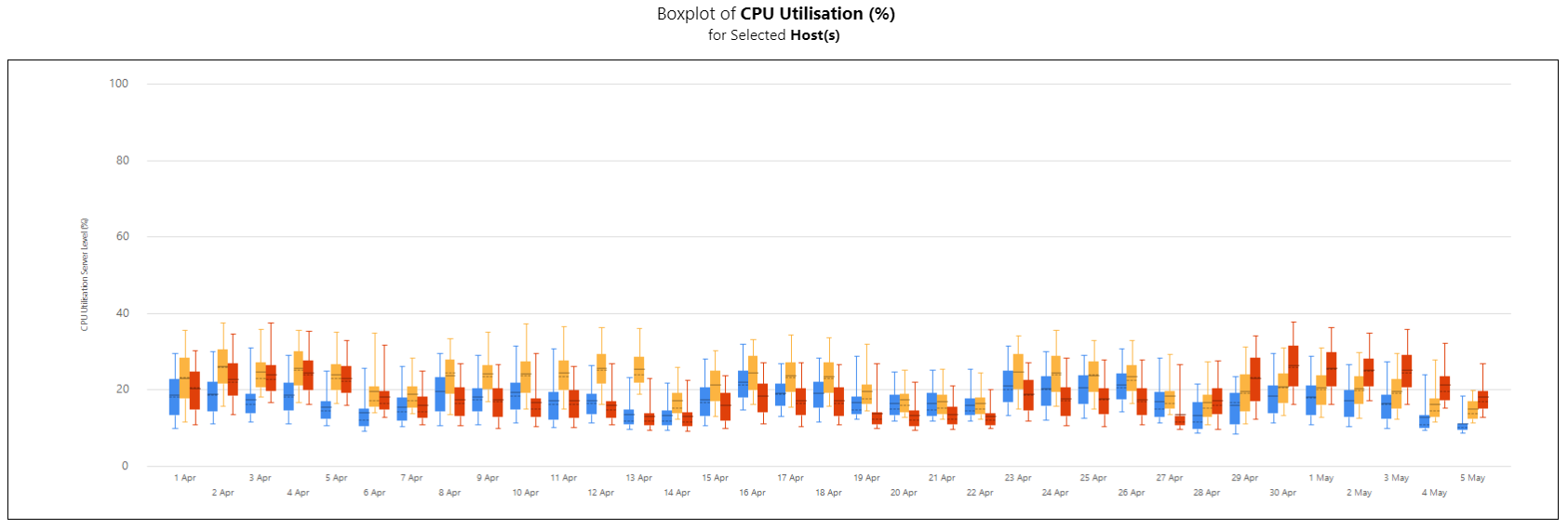
Informe de gráficos de barras:

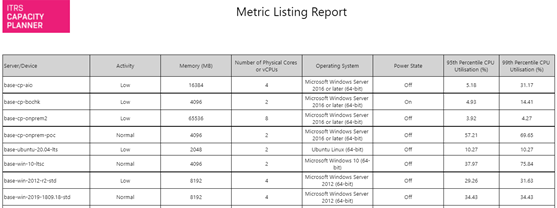
Listado de métricas Copied
Este es un informe flexible que permite una visualización tabular de entidades seleccionadas con hasta 20 columnas de métricas y 20 columnas de propiedades.
Parámetros del informe Copied
Below are the parameters used to configure this report. For information on parameters that are common across reports, such as entities or grouping filters, see Report parameters.
- Groupings to display — se pueden seleccionar hasta 20 propiedades para mostrar. Si se seleccionan más, solo se muestran las primeras 20.
- Metric(s) — seleccione una o más métricas.
- Percentile/value — se puede seleccionar uno o más percentiles para cada métrica.
- Summarise by grouping — los datos pueden mostrarse a nivel de servidor o por valor de agrupación.
- Grouping aggregations — esta opción solo está disponible donde se ha seleccionado Summarise by grouping. Permite aplicar una agregación máx, mín, media o suma a cada percentil seleccionado.
Ejemplo Copied
In the image below, you can see an example of an output of this report.
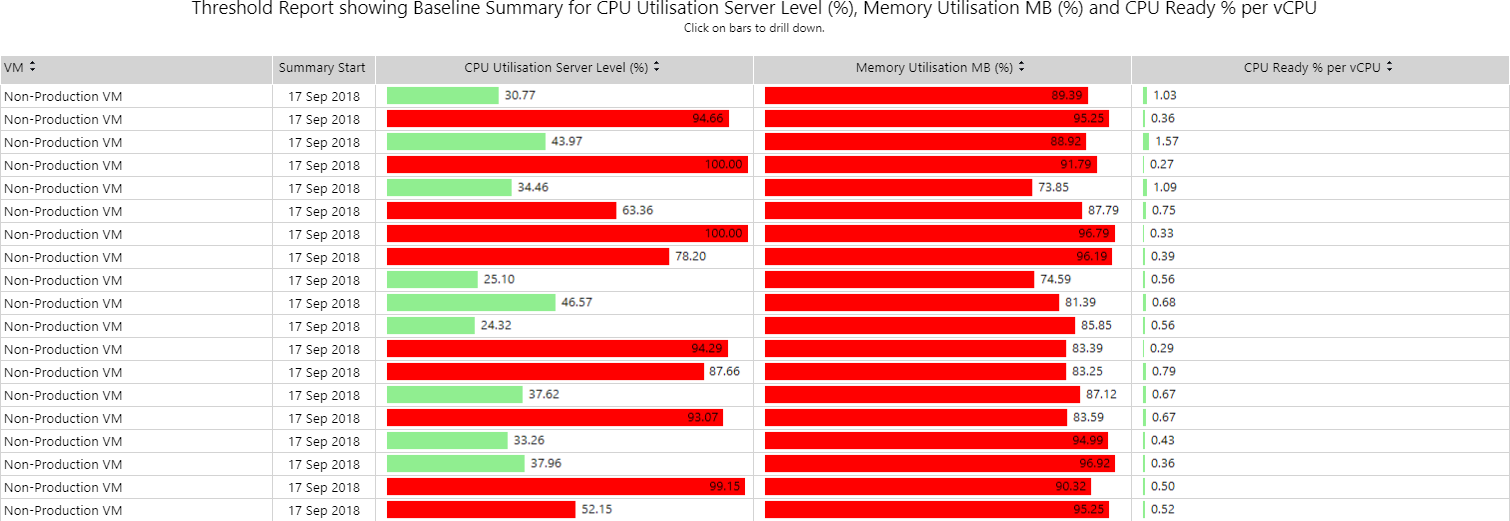
Análisis de umbral de métricas Copied
Este informe le permite seleccionar una medida estadística para cualquier métrica y usarla en combinación con un umbral. La medida es una indicación de cuánto tiempo total en el período de base seleccionado esa métrica ha estado por encima del umbral especificado. Puede seleccionar hasta 3 métricas para verificaciones de violación de umbral.
El informe se presenta en un formato tabular visual de gráficos de barras horizontales. Una barra se muestra en rojo si se cruzó un umbral.
Puede profundizar en las medidas e investigar los datos de series temporales para la combinación de entidad/métrica. Para hacer esto, haga clic en la barra de la entidad seleccionada.
Ejemplo Copied
In the image below, you can see an example of an output of this report. Muestra el pico de CPU, memoria y CPU ready% por VCPU durante todo el período de base.
Percentiles de umbral de métricas Copied
Este informe muestra todos los valores estadísticos para las entidades seleccionadas para una métrica dada. Los valores estadísticos disponibles son: mínimo, percentil 5, percentil 25, percentil 50 (mediana), media, percentil 75, percentil 95, percentil 99, máximo y último valor.
Un filtro de umbral está disponible para ver solo aquellas entidades que han superado un umbral definido por el usuario. Para usar esta función, seleccione valores para Filter Operator y Filter Threshold. Esto es particularmente útil para identificar servidores muy ocupados o inactivos. También está disponible una vista de gráfico de caja seleccionando el tipo de Chart display.
Puede profundizar en más gráficos y series temporales para cualquier entidad en la tabla o gráfico. Para hacer esto, haga clic en el nombre de la entidad en la tabla o en el gráfico de caja en el gráfico.
Ejemplo Copied
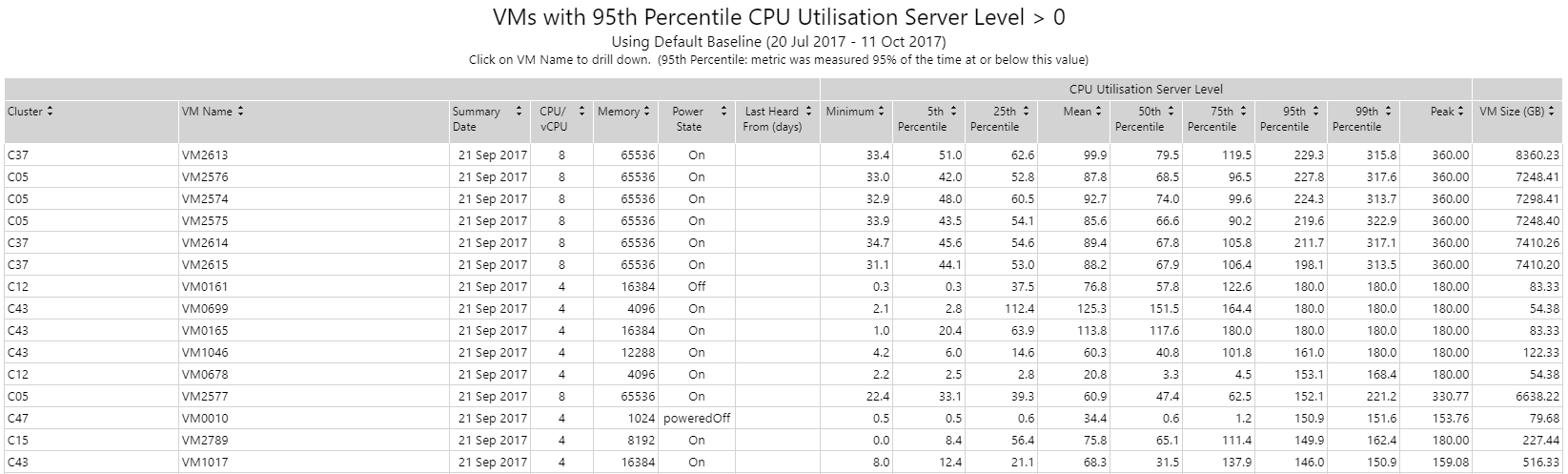
In the image below, you can see an example of an output of this report. Muestra todas las VMs donde el percentil 95 de CPU es mayor que un valor especificado. En este caso, usar 0 muestra todas las medidas para esta métrica para todas las máquinas.
Eventos operativos Copied
Este informe enumera los eventos generados por Capacity Planner en su propiedad. Puede mostrar todos los eventos o filtrarlos por vista de base, métrica, tipo de entidad y valores de agrupación seleccionados.
Hay dos secciones en el informe:
- La sección de resumen enumera todos los eventos, sus fechas previstas, métrica y niveles de gravedad.
- La sección detallada muestra una serie temporal de la métrica especificada, niveles de gravedad, período de entrenamiento de predicción y los puntos en los que se prevé que la serie temporal supere los niveles relevantes.
Parámetros del informe Copied
Below are the parameters used to configure this report. For information on parameters that are common across reports, such as entities or grouping filters, see Report parameters.
- Report title — le permite especificar un título de informe personalizado.
Ejemplo Copied
In the image below, you can see an example of an output of this report.
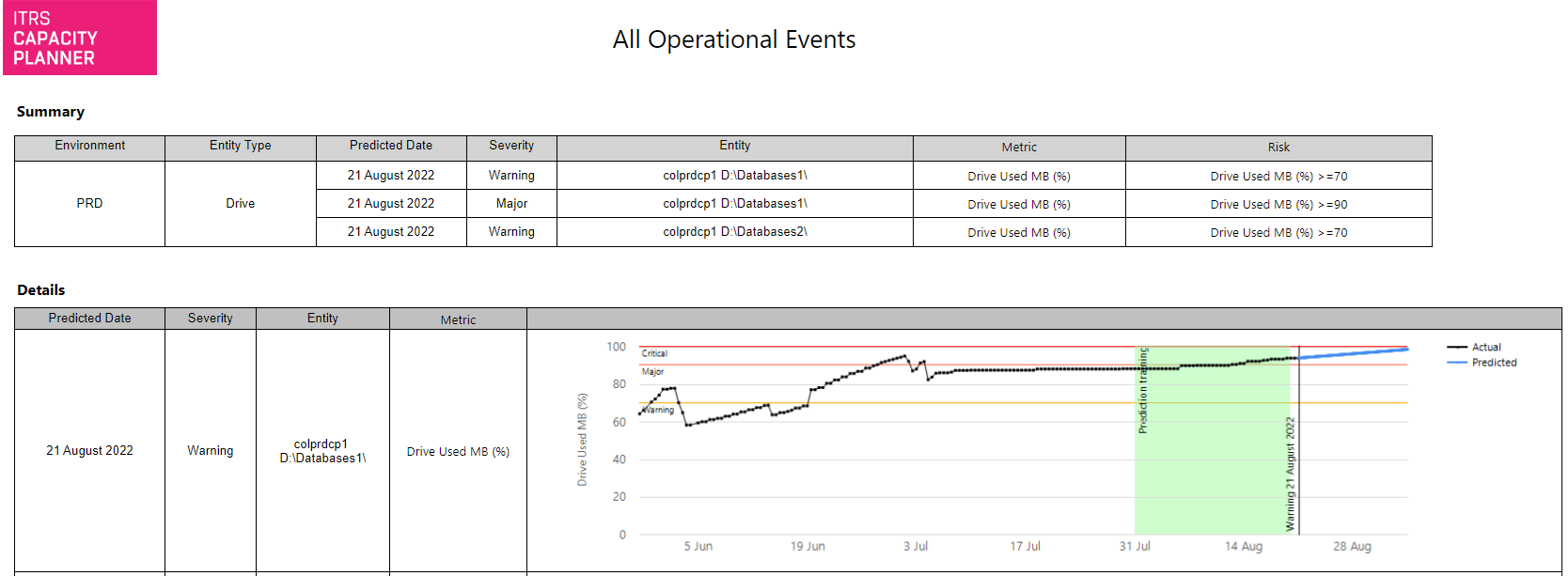
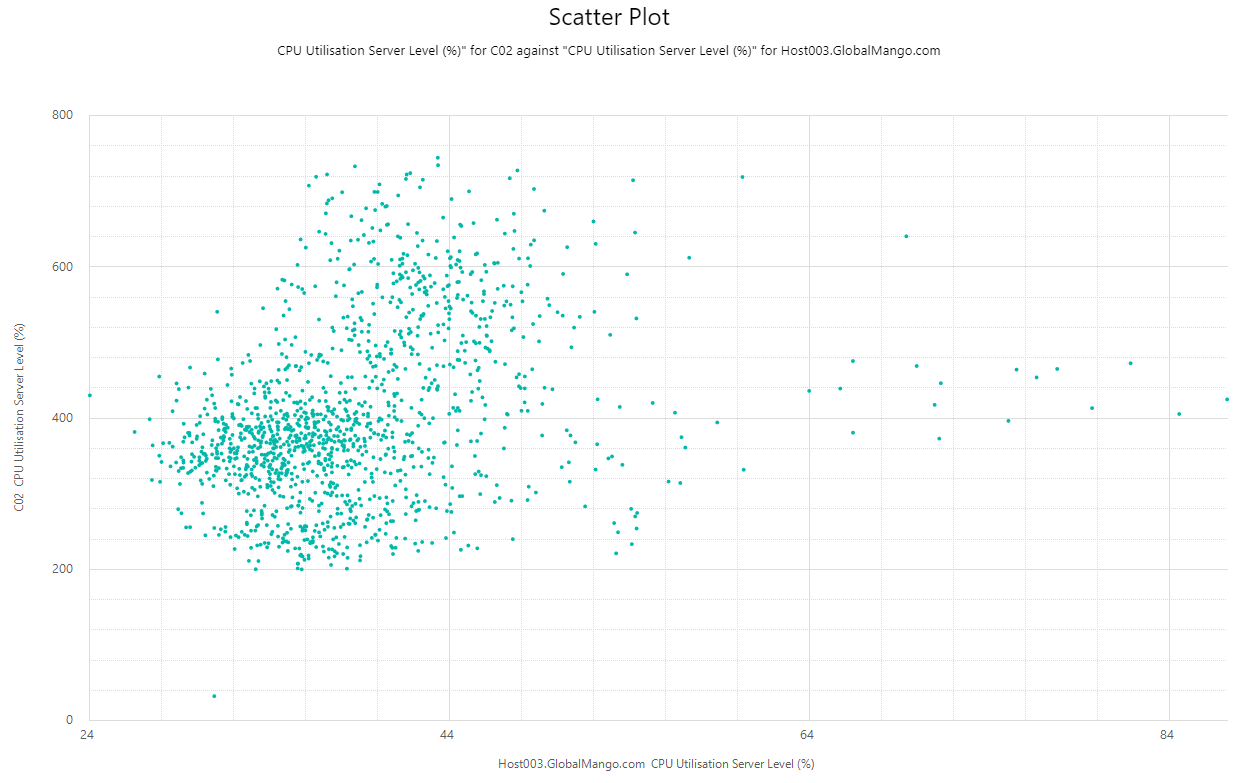
Gráfico de dispersión Copied
Este informe le permite generar un gráfico de dispersión que muestra los valores de pares de métricas de cualquier par de entidades.
Ejemplo Copied
In the image below, you can see an example of an output of this report.
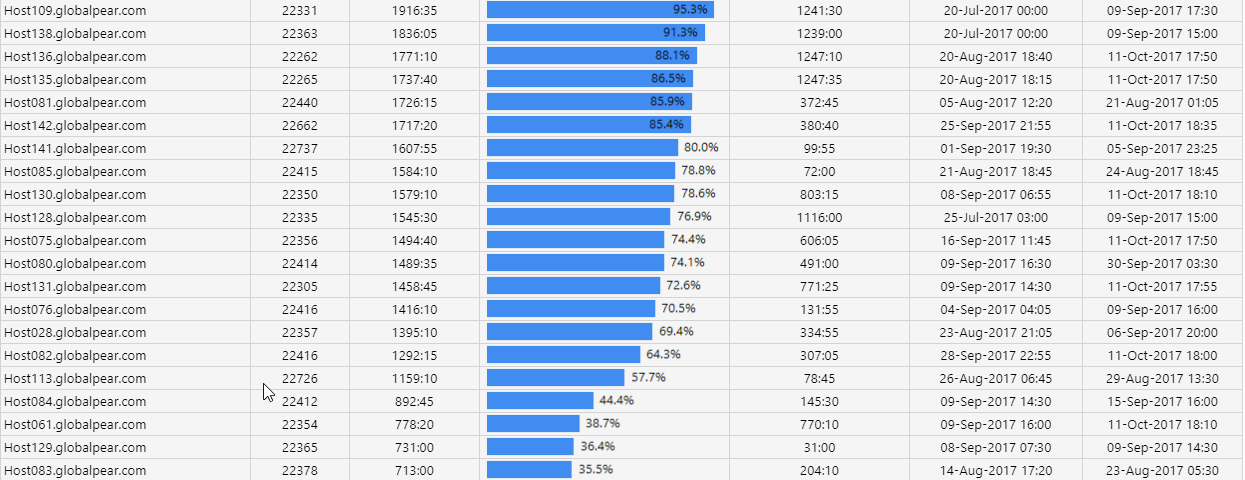
Tiempo por encima del umbral Copied
Este informe le permite seleccionar una base, grupo de entidades y una métrica, y determinar el tiempo total pasado por encima de un umbral dado para cada entidad. También puede identificar el período de tiempo más largo en el que estuvo por encima de ese umbral. Puede filtrar los resultados aún más por días de la semana y hora del día.
Puede profundizar en la duración del episodio más largo para una serie temporal detallada de cuándo ocurrió ese episodio.
Ejemplo Copied
In the image below, you can see an example of an output of this report.
VMs infrautilizadas, inactivas y con recursos insuficientes Copied
Este informe identifica máquinas virtuales a lo largo del período de base que están infrautilizadas, inactivas (tienen niveles muy bajos de utilización de CPU) o con recursos insuficientes según los ajustes de dimensionamiento adecuado proporcionados y brinda recomendaciones adecuadas. Por defecto, estos ajustes se toman de la vista de base pero se pueden cambiar en los parámetros del informe. Se muestran valores de pico, percentil 99, percentil 95 y media para cada VM y por defecto los informes se ordenan por utilización de CPU de pico (de menor a mayor).
Este informe le permite identificar rápidamente las VMs que se pueden apagar o aquellas que pasan una cantidad significativa de tiempo inactivas, con tiempos muy pequeños de actividad máxima.
Parámetros del informe Copied
Below are the parameters used to configure this report. For information on parameters that are common across reports, such as entities or grouping filters, see Report parameters.
Report Sections to Include — este informe se divide en tres secciones: VMs Inactivas, VMs Infrautilizadas y VMs con Recursos Insuficientes. Puede decidir qué secciones mostrar.
Tenga en cuenta que si selecciona más de una sección, se muestran una tras otra, por lo que, dependiendo de cuántos datos muestre su informe, es posible que tenga que avanzar por las páginas del informe para ver la siguiente sección. Cuando se exporta a Excel, las tres secciones se muestran en hojas de cálculo separadas.
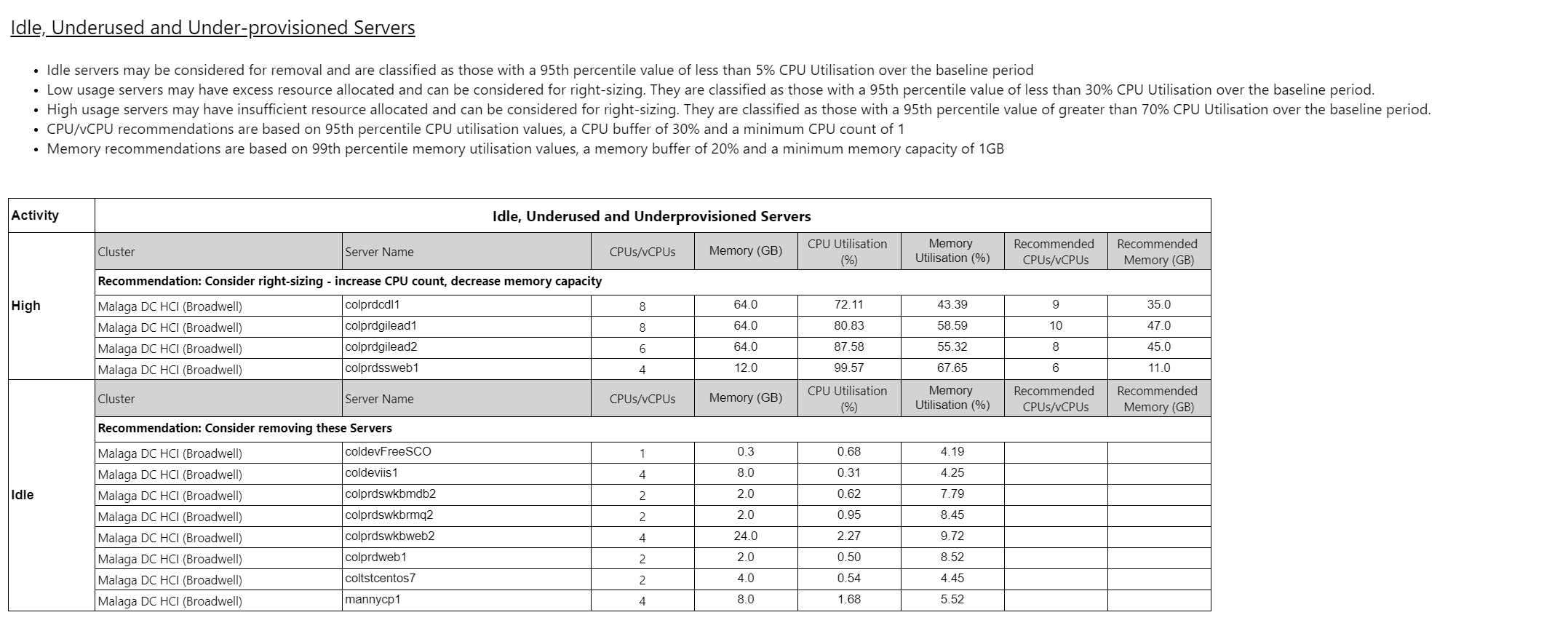
Server CPU Percentage — estos parámetros controlan cómo se clasifican los servidores dentro del informe:
- Idle Server CPU Percentage — el nivel al que se considera inactiva la VM si el percentil de CPU está por debajo de él.
- Low Server CPU Percentage — el nivel al que se considera infrautilizada la VM si el percentil de CPU está por debajo de él.
- High Server CPU Percentage — el nivel al que se considera con recursos insuficientes la VM si el percentil de CPU está por debajo de él.
Right-size CPU/Memory parameters — indique las medidas que está utilizando en todo el informe:
-
Right-size CPU/Memory Percentile — el valor del percentil utilizado en los cálculos y recomendaciones de dimensionamiento adecuado en todo este informe.
-
Right-size Minimum CPUs — la configuración mínima de CPU permitida al recomendar una nueva configuración para las VMs.
-
Right-size Minimum Memory Capacity (GB) — la capacidad mínima de memoria permitida al recomendar una nueva configuración para las VMs.
-
Right-size CPU (%) — el porcentaje de capacidad que debe reservarse al dimensionar adecuadamente para asegurar que el percentil de demanda de CPU no esté por encima del nivel de buffer de capacidad.
-
Right-size Memory Buffer (%) — el porcentaje de capacidad que debe reservarse al dimensionar adecuadamente para asegurar que el percentil de demanda de memoria no esté por encima del nivel de buffer de capacidad.
Ejemplo Copied
In the image below, you can see an example of an output of this report.
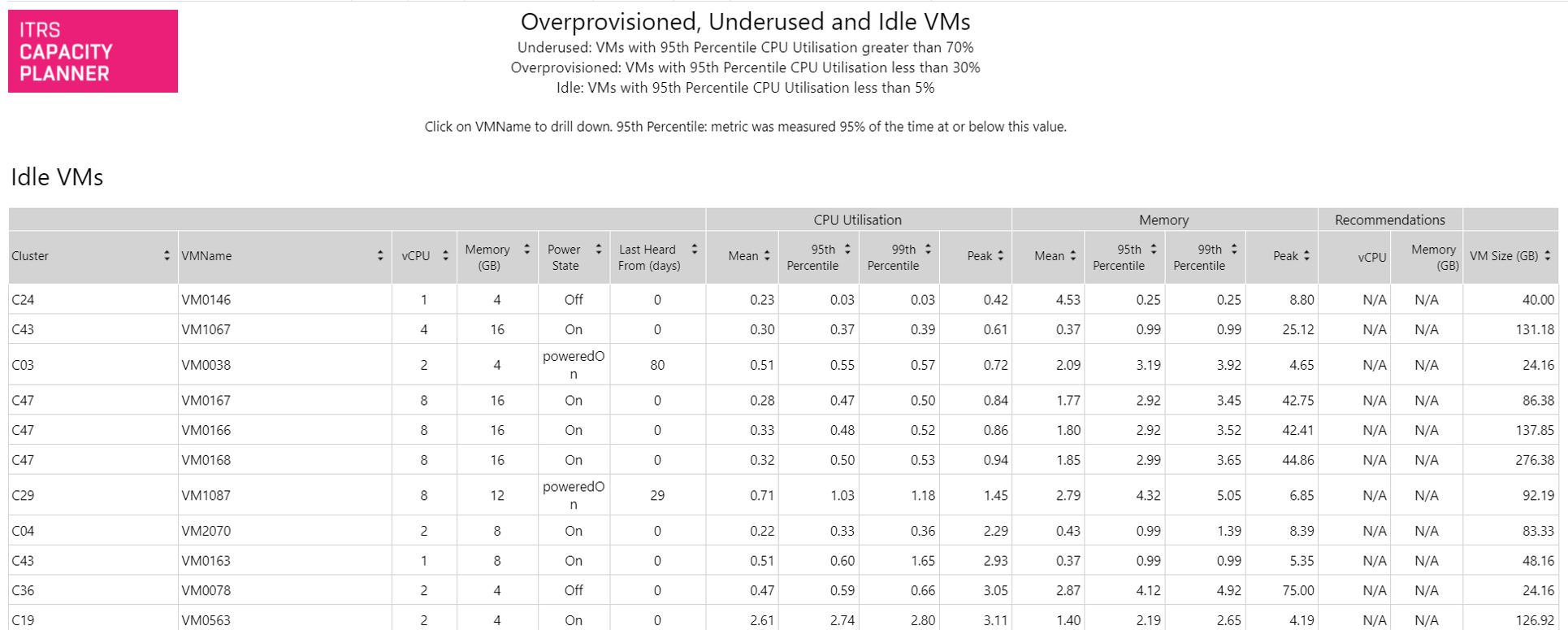
La ordenación por defecto se puede cambiar haciendo clic en las flechas sobre cada columna para ordenar por esa columna.
Resumen de almacenamiento de VM Copied
Este informe muestra la comparación entre el almacenamiento asignado a una máquina virtual y el almacenamiento utilizado por los discos del sistema operativo de la máquina virtual. Se puede utilizar para identificar el desperdicio potencial de almacenamiento en un entorno. El informe está ordenado por las VMs más derrochadoras. Cuando se genera el informe, puedes expandir los detalles del disco para obtener más información sobre los discos de las VMs y la utilización en comparación con el almacenamiento grueso asignado.
Al filtrar los datos que deben mostrarse en el informe, puedes especificar el estado de la VM, Current o Removed. Las VMs actuales son aquellas que todavía están generando datos activamente.
Para trabajos de investigación o exploración, recomendamos usar el estado Current para informes.
Ejemplo Copied
In the image below, you can see an example of an output of this report.
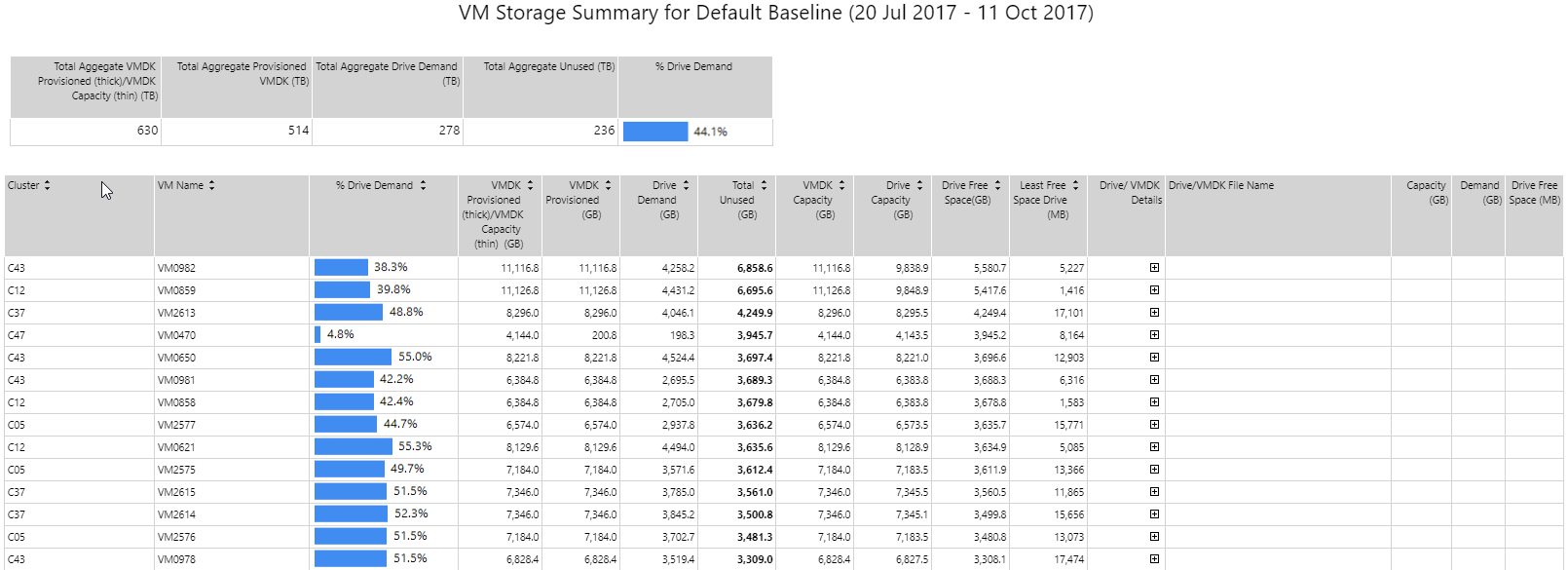
Infraestructura de servicio Copied
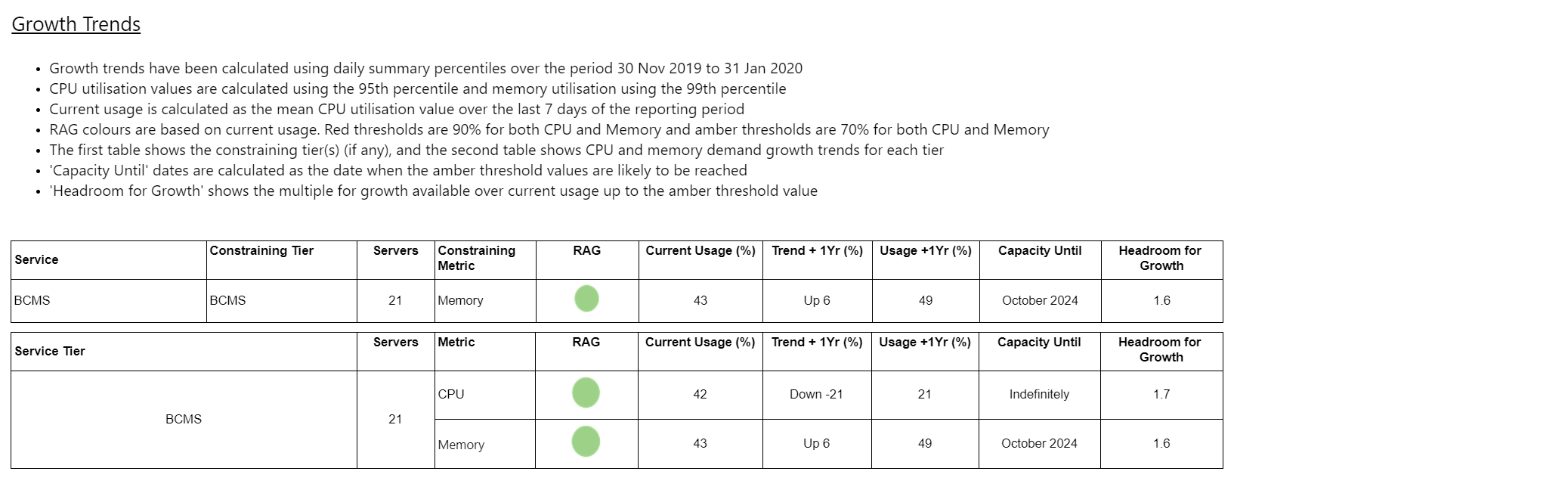
Este informe te permite seleccionar un agrupamiento de cargas de trabajo y determinar la tendencia a largo plazo agregada en la utilización de CPU y memoria en todas las cargas de trabajo, informar sobre la actividad del servidor y los riesgos de operación a corto plazo descubiertos a través de algoritmos de tendencia avanzados.
Su propósito es proporcionar un único informe que cubra todo lo necesario para presentar un resumen de capacidad completo para una aplicación, servicio o cualquier colección común de servidores que comparten un valor de agrupamiento de Capacity Planner. Proporciona tendencias a largo plazo para la capacidad y recomendación sobre la actividad del servidor.
El informe muestra un resumen del servicio con la siguiente información:
- Una lista de máquinas inactivas, sobreprovisionadas y subprovisionadas junto con recomendaciones de redimensionamiento.
- Cuándo se cruzarán los umbrales de capacidad.
- Margen para el crecimiento.
- Eventos operativos a corto plazo en orden de criticidad (alto, inactivo, bajo).
- Riesgos del servicio — recursos que requieren atención urgente.
- Diagramas de caja para todos los servidores y series temporales de tendencias.
Cuando exportas el informe, puedes hacer clic a través del resumen del servidor en la página de resumen ejecutivo del informe para ver la representación detallada del diagrama de caja.
Hay varios componentes en este informe:
- El resumen ejecutivo
- Una visión general de alto nivel de las tendencias
- Resumen de la actividad del servidor
- Resumen de los riesgos del servidor
- Detalle sobre las tendencias
- Detalle sobre la actividad del servidor
- Detalle sobre los riesgos del servicio
Cuando configuras el informe y seleccionas los parámetros Service Grouping y Service Grouping Values, los parámetros restantes se llenan con valores predeterminados que pueden ser cambiados.
Parámetros del informe Copied
Below are the parameters used to configure this report. For information on parameters that are common across reports, such as entities or grouping filters, see Report parameters.
| Parámetro | Descripción |
|---|---|
| Agrupación del servicio | El nombre del agrupamiento utilizado para filtrar el alcance del servidor de informes. |
| Valor de agrupación del servicio | El valor del agrupamiento. |
| Subgrupo del servicio | Si el modelado de un servicio se hace más complejo por servicios compartidos, este parámetro permite incluir otros valores de agrupamiento en el informe. |
| Nombre de visualización del servicio | El nombre utilizado en la parte superior del informe para describir el servicio. Si se deja en blanco, se utiliza el Service grouping value. |
| Nivel del servicio | Si se utiliza un agrupamiento para definir niveles de una aplicación, se puede definir aquí. Esto asegura que cada nivel esté separado en el informe y se tendencia por separado. |
| Modelo de tendencia de crecimiento | El modelo utilizado para calcular tendencias a largo plazo. |
| Tipo de rango de datos de tendencia de crecimiento | Define el punto en los datos desde el cual el informe comienza a mirar hacia atrás. |
| Rango relativo de tendencia de crecimiento | Especifica cuánto mira hacia atrás el informe. |
| Número de periodos de tiempo de tendencia de crecimiento | Especifica cuántos periodos de tiempo se utilizan en la tendencia. Por ejemplo, si el valor es 6, esto significa que el rango de tendencia predeterminado es de 6 meses completos del calendario. |
| Umbral rojo de CPU de tendencia de crecimiento | El nivel de la tendencia a largo plazo que se marcaría como rojo en el resumen de tendencia. |
| Umbral ámbar de CPU de tendencia de crecimiento | El nivel de la tendencia a largo plazo que se marcaría como ámbar en el resumen de tendencia. |
| Percentil de CPU de tendencia de crecimiento | La medida diaria del percentil. |
| Umbral rojo de memoria de tendencia de crecimiento | El nivel de la tendencia a largo plazo que se marcaría como rojo en el resumen de tendencia. |
| Umbral ámbar de memoria de tendencia de crecimiento | El nivel de la tendencia a largo plazo que se marcaría como ámbar en el resumen de tendencia. |
| Percentil de memoria de tendencia de crecimiento | La medida diaria del percentil. |
| Número de días para el uso actual | El uso actual es el valor promedio del percentil agregado seleccionado. Cuando determinas el uso actual en el resumen, esto define el número de días a utilizar. |
| Opción de visualización de tendencia de crecimiento | Determina si se utilizan valores brutos agregados o porcentajes en la tendencia. |
| Porcentaje de CPU del servidor inactivo | El nivel en el que se considera inactivo el servidor si el percentil de CPU cae por debajo de él. |
| Porcentaje de CPU del servidor de baja actividad | El nivel en el que se considera de baja actividad el servidor si el percentil de CPU cae por debajo de él. |
| Porcentaje de CPU del servidor de alta actividad | El nivel en el que se considera de alta actividad el servidor si el percentil de CPU cae por debajo de él. |
| Percentil de CPU para redimensionar | El valor del percentil utilizado en los cálculos y recomendaciones de redimensionamiento. |
| CPUs mínimas para redimensionar | La configuración mínima de CPU permitida al recomendar una nueva configuración para las VMs. |
| Percentil de memoria para redimensionar | El valor del percentil utilizado en los cálculos y recomendaciones de redimensionamiento. |
| Memoria mínima para redimensionar (GB) | La capacidad mínima de memoria permitida al recomendar una nueva configuración para las VMs. |
| Búfer de memoria para redimensionar | El porcentaje de capacidad que debe reservarse al redimensionar para asegurar que el percentil de demanda de memoria no esté por encima del nivel de búfer de capacidad. |
Ejemplo Copied
A continuación, puede ver ejemplos de un informe de salida.
Resumen ejecutivo Copied

Resumen de tendencias Copied
Resumen de actividad del servidor Copied
Resumen de riesgos del servicio Copied

Detalle sobre tendencias Copied
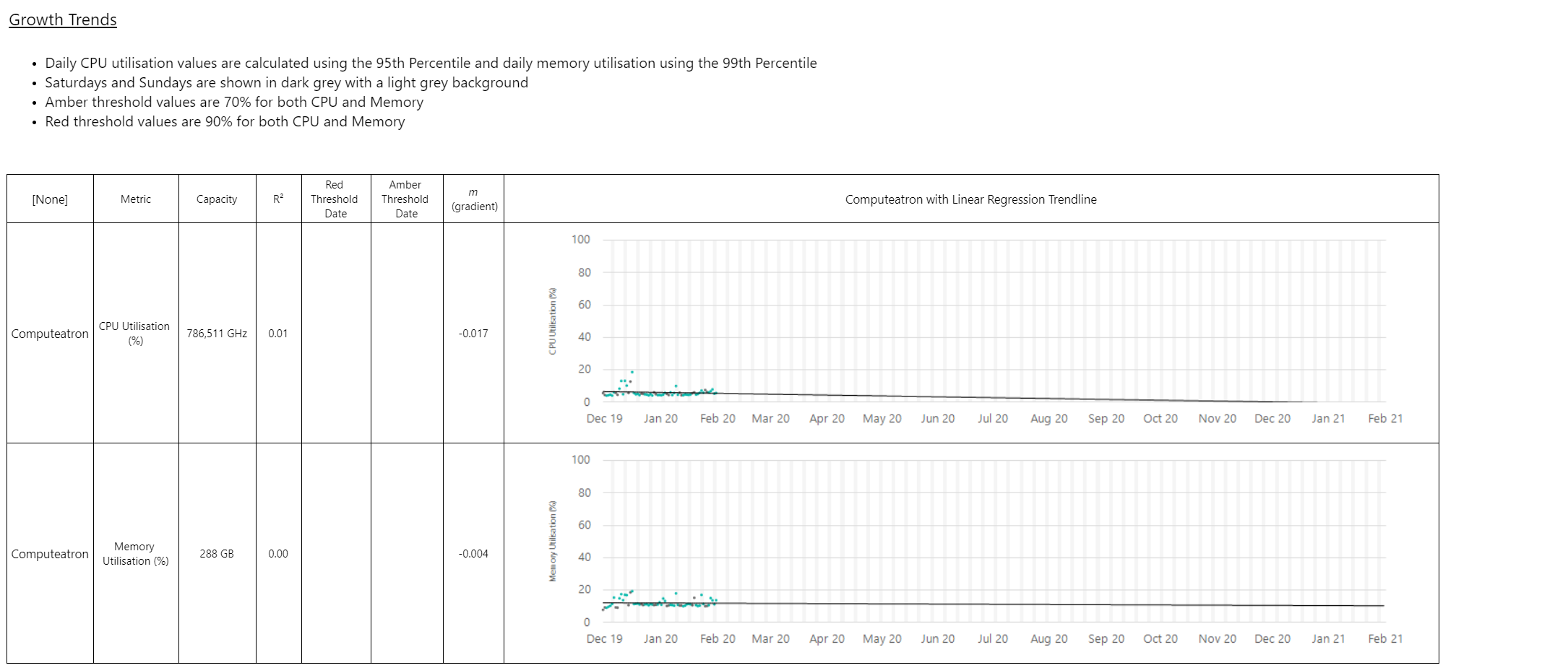
Detalle sobre actividad del servidor Copied
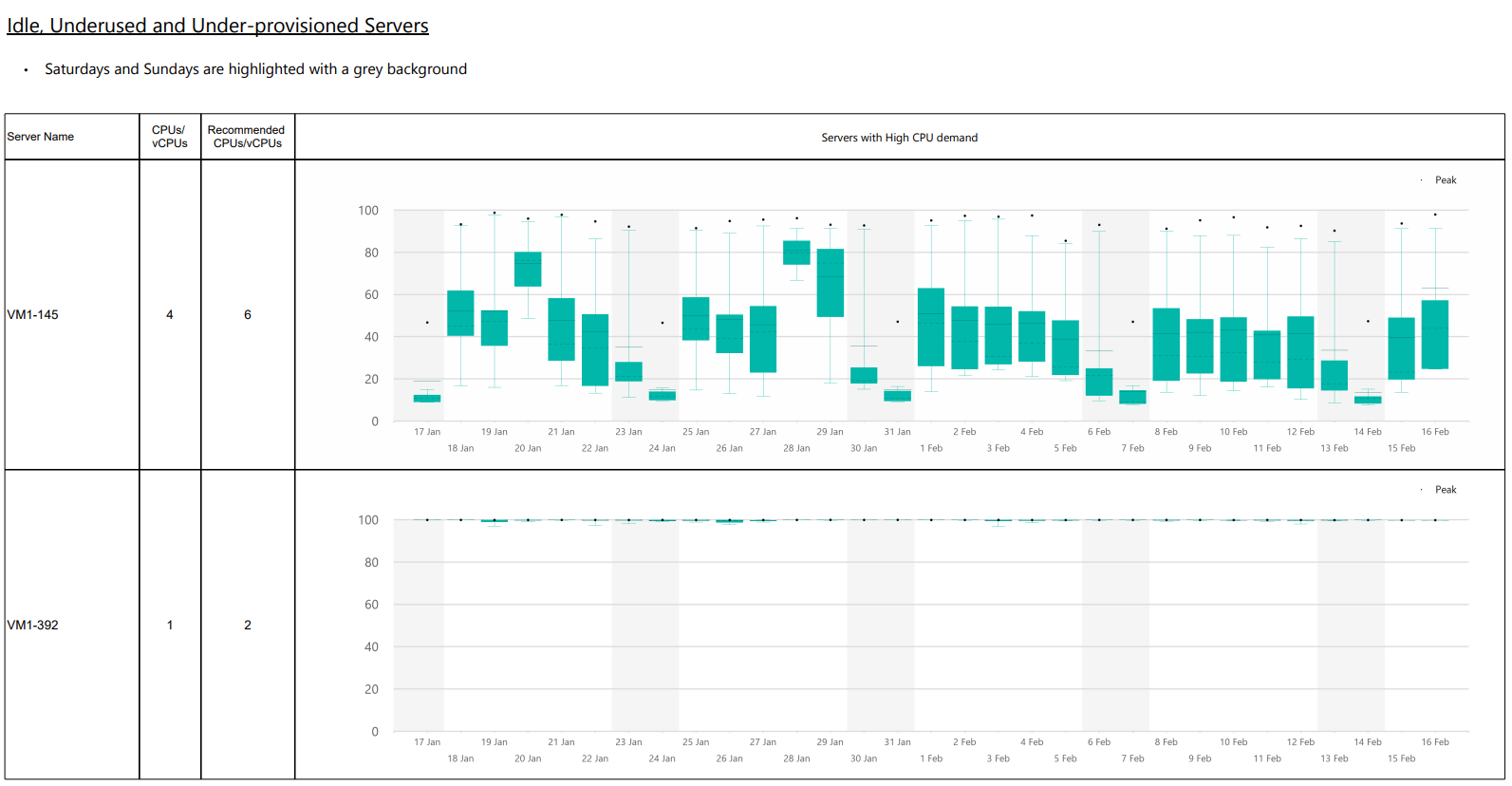
Detalle sobre riesgos del servicio Copied

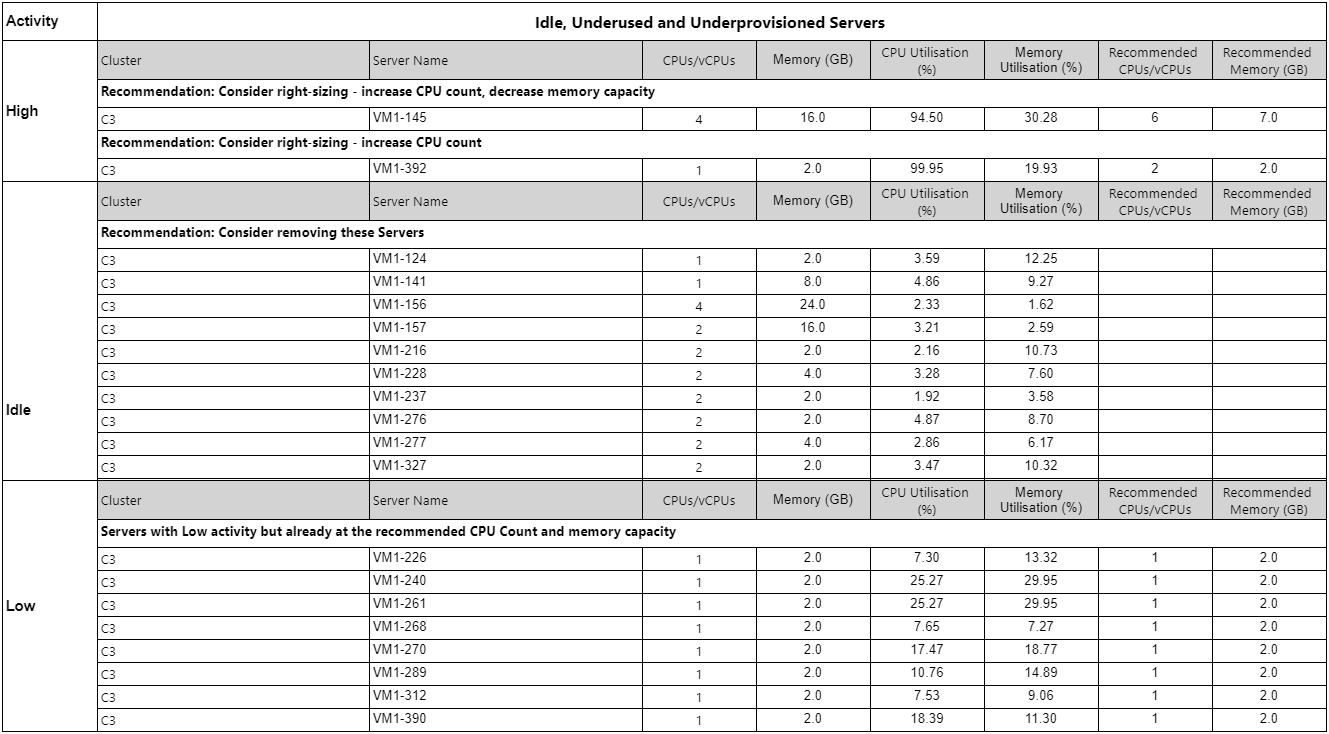
Otros informes Copied
Además de estos informes avanzados, también puede crear informes de Servicio, Infraestructura y Escenario directamente desde un modelo de Vista Basal o Escenario de Pensamiento Futuro.
Para más información, vea Informes de infraestructura y servicio y Informes de escenario.