Tareas de recopilación
Collection tasks provide data from different systems. This data is then sent to and displayed in the sunburst.
All your existing collection tasks are displayed in the main Collection Manager window. From here, you can edit them and create new tasks.
Esta página explica en detalle cómo hacerlo y qué configuraciones están disponibles para tareas de recopilación de diferentes tipos.
Editor de tareas Copied
Cada editor de tareas de recopilación contiene opciones y propiedades comunes. Estas se muestran en el lado izquierdo del editor. Adicionalmente, cada tarea específica contiene opciones disponibles solo para ese tipo de tarea. Estas se explican en las secciones a continuación.
Configuraciones comunes del editor de tareas:
| Propiedad | Descripción |
|---|---|
| Nombre | El nombre de la tarea a crear. Este también es el nombre bajo el cual esta tarea activa aparecerá en el Programador de Tareas de Windows. Si no se proporciona un nombre, se crea un nombre predeterminado. |
| Proyecto | El proyecto de Capacity Planner al que se subirán los datos. Si solo un proyecto está disponible para su cuenta de usuario, entonces se selecciona automáticamente. Si no está seguro de cuál es el nombre de su proyecto, contacte a su representante de cuenta de ITRS para verificar el nombre y ID del proyecto correcto. |
| Primera recopilación | Si la tarea de recopilación no se ha ejecutado antes, este valor especifica el número de horas anteriores de datos a muestrear cuando se ejecute la tarea. Si no se proporciona un valor, se muestrean las 24 horas anteriores de datos. |
| Segunda recopilación | Si selecciona esta opción, esto especifica el número de días anteriores de datos recopilados tan pronto como la primera recopilación se completa con éxito. Todas las recopilaciones subsiguientes continúan desde el final de la recopilación anterior. |
| Nombre de usuario | El nombre de la cuenta de usuario que se utilizará para ejecutar la tarea programada. El usuario debe tener configuradas las políticas de seguridad locales para Logon as a batch job, y Logon as a service. Para más información, vea Crear un usuario de Windows para tareas programadas. |
| Contraseña | La contraseña para la cuenta de usuario que se utilizará para ejecutar la tarea programada. |
| Crear tarea programada | Si se selecciona, especifica la hora a la que se debe ejecutar la tarea y con qué frecuencia debe repetirse. Si no se selecciona, aún se creará una tarea programada, pero solo se podrá ejecutar manualmente, según sea necesario. |
| Comenzar en | La hora de inicio de la tarea programada. |
| Repetir cada | La frecuencia con la que se debe repetir la tarea. Las opciones disponibles son 12 horas, 6 horas y personalizado, lo que le permite especificar el intervalo de tiempo. |
Editor de scripts de recopilación Copied
El editor de scripts de recopilación es utilizado por ciertos tipos de tareas de recopilación para editar los detalles del script de recopilación cuando sea necesario.
La primera vez que abre el editor de scripts para una tarea, se llena con el script predeterminado para esa tarea, por ejemplo, un script de Dynatrace para Dynatrace, un script de Geneos para Geneos.
Si realiza alguna edición al script y luego hace clic en Load default, se borrarán las ediciones y se recargará el script predeterminado.
Nota
Recomendamos que use el script predeterminado distribuido con el Data Collector.
Haga clic en Validate para verificar si el archivo JSON tiene un formato válido.
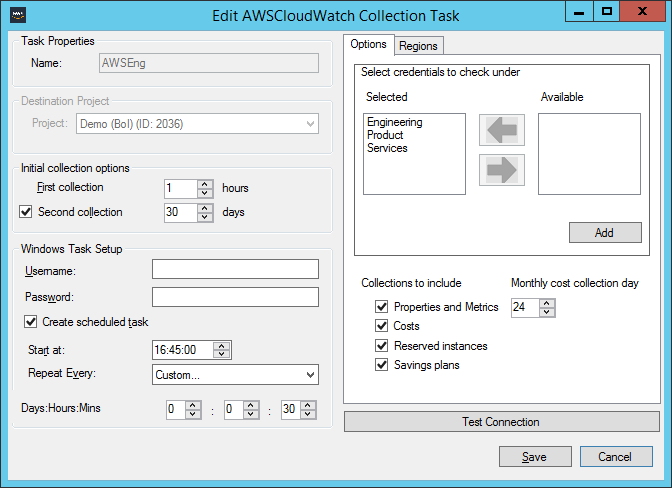
Tarea de recopilación de AWS Copied
La tarea de Cloudwatch de AWS recopila propiedades, métricas, costos, instancias reservadas y planes de ahorro de Amazon Web Servers (AWS).
Note that when extracting data from cloud providers, Capacity Planner the data collectors are run from the environment using secure read-only credentials provided by the customer. This avoids unnecessary network transfer, the need to upgrade and maintain on-premise data collectors, and ensures that data collection is always at the most up-to-date release.
Recomendamos que el Data Collector tenga acceso a AWS CloudTrail, para asegurar que se recolecten datos y costos de instancias temporales de AWS.
- Si el acceso a CloudTrail está disponible, entonces la tarea de recopilación se puede ejecutar una vez cada 24 horas.
- Si el acceso a Cloudtrail no está disponible, entonces la tarea de recopilación debe ejecutarse al menos cada hora para intentar capturar todas las instancias temporales de AWS.
Además de las recopilaciones regulares, una recopilación de costos de 31 días se puede ejecutar una vez al mes para recuperar todos los costos reales del sistema.
El editor de tareas de AWS tiene dos pestañas que se utilizan para configurar la tarea de recopilación:
- Options para seleccionar credenciales y seleccionar qué datos recopilar.
- Regions.
Seleccionar y añadir credenciales Copied
En la pestaña Options, seleccione las credenciales requeridas en la lista Available y añádalas a la lista seleccionada haciendo clic en la flecha.
Varias credenciales pueden ser seleccionadas a la vez usando las teclas Ctrl o Shift.
Si las credenciales requeridas no están disponibles, puede añadirlas haciendo clic en el botón Add:
Fill in the form to add credentials:
- Profile name is used to identify this profile.
- Access ID — AWS Access ID supplied for this account.
- Secret Access Key — the AWS Secret Access Key supplied for this account.
- Region — the region used when logging in to AWS clients.
- Use for costs — identifies which credentials should be used for monthly actual cost collection.
Incluir colectores Copied
Para aprovechar al máximo Capacity Planner, todas las opciones en la sección Collectors to include deben ser seleccionadas. Sin embargo, en algunas circunstancias, puede ser deseable excluir algunas opciones o dividir diferentes opciones en más de una tarea de recopilación. Por ejemplo:
- Si su organización no utiliza planes de ahorro o instancias reservadas, puede desear excluirlos.
- Si CloudTrail no es accesible, puede querer recopilar propiedades y métricas cada hora, y las otras opciones diariamente.
Día de recopilación de costos mensual Copied
Las recopilaciones de costos ocurren a la 1 PM hora local diariamente. Estas recopilaciones de costos recuperan costos estimados para los tres días anteriores.
Una vez al mes, esto es reemplazado por una recopilación de costos mensual, que recupera costos reales desde el primer hasta el último día del mes anterior.
El Monthly cost collection day especifica en qué día le gustaría que ocurra la recopilación de costos mensual.
Seleccionar regiones Copied
En la pestaña Regions, puede especificar un subconjunto de regiones para recuperar datos.
Por defecto, la tarea de recopilación intentará acceder a todas las regiones que estén disponibles para cada conjunto de credenciales seleccionadas. Para buscar un subconjunto de regiones, marque Search selected regions y seleccione al menos una región de la lista Available.
La tarea de recopilación recorrerá cada región seleccionada con cada conjunto de credenciales y, si esas credenciales tienen acceso a esa región, la tarea recopilará los datos requeridos.
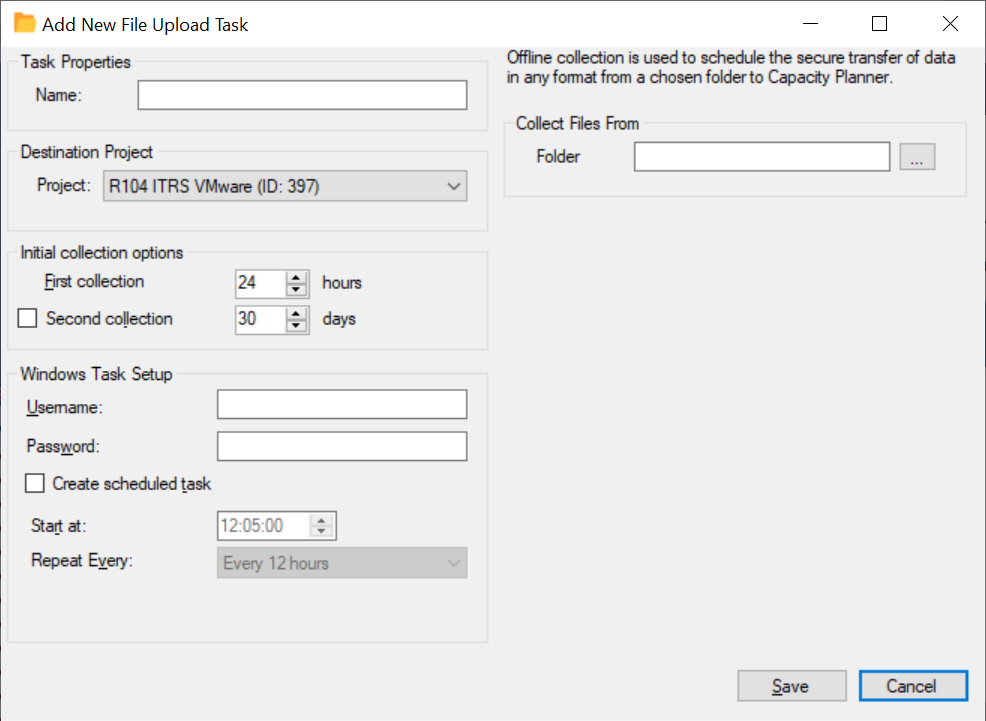
Tarea de colección de subida de archivos Copied
Las colecciones de subida de archivos leen archivos de una carpeta especificada y los suben a Capacity Planner para su procesamiento.
Este tipo de tarea de colección se utiliza para subir datos producidos por aplicaciones y scripts de terceros.
Además de las propiedades genéricas de la tarea, el editor de tareas de subida de archivos requiere la carpeta de la cual recolectar archivos. Esto puede incluir un comodín para los nombres de archivos, por ejemplo C:\MiCarpeta\*.zip.
Nota
Solo se subirán los archivos dentro de la carpeta especificada, los subdirectorios bajo esa carpeta no serán buscados.
El comodín predeterminado para los nombres de archivos es * . *, lo que significa que se ignoran los archivos sin extensión.
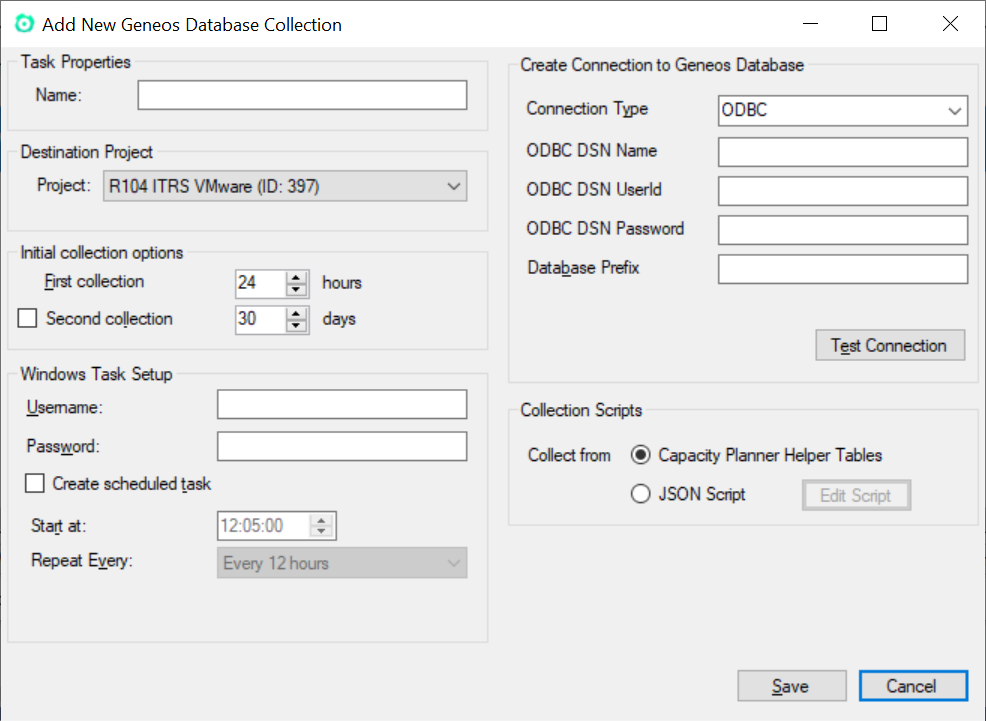
Tarea de colección de Geneos Copied
La forma recomendada de recolectar datos de Geneos es usar las tablas auxiliares de Capacity Planner en Geneos. Para más información, vea Crear tablas de base de datos en auxiliar. Para más información, contacte a su representante de cuenta de ITRS.
Todos los controladores ODBC necesarios deben estar configurados antes de la recolección. Para más información, vea Controladores ODBC.
Tipo de conexión Copied
Además de las propiedades genéricas de la tarea, el editor de tareas de Geneos requiere especificar si la conexión a la base de datos utilizada para recolectar datos es ODBC u Oracle. Cada uno requiere diferentes parámetros:
ODBC Copied
| Valor | Descripción |
|---|---|
| Nombre DSN ODBC | El nombre de la conexión ODBC a los datos fuente. |
| Usuario DSN ODBC | El ID de usuario ODBC que se utilizará con la conexión ODBC. |
| Contraseña DSN ODBC | La contraseña para el usuario ODBC. |
| Prefijo de base de datos (opcional) | El nombre del esquema de base de datos a utilizar. |
Oracle Copied
| Valor | Descripción |
|---|---|
| Nombre de host de Oracle | El nombre de la base de datos Oracle que contiene los datos fuente. |
| ID de usuario de Oracle | El ID de usuario de Oracle que se utilizará para conectar. |
| Contraseña de Oracle | La contraseña para el ID de usuario de Oracle. |
| SID de Oracle | El ID del sistema utilizado para identificar la base de datos. |
| Número de puerto de Oracle | El número de puerto para la conexión. |
La conexión se puede probar usando el botón Test connection.
Script de colección Copied
The collection script is specifically configured to collect all the information required by , Capacity Planner and it is not recommended that it be altered.
If there is a requirement to edit the collection script, click Edit Collection Script. For more information, see Collection script editor.
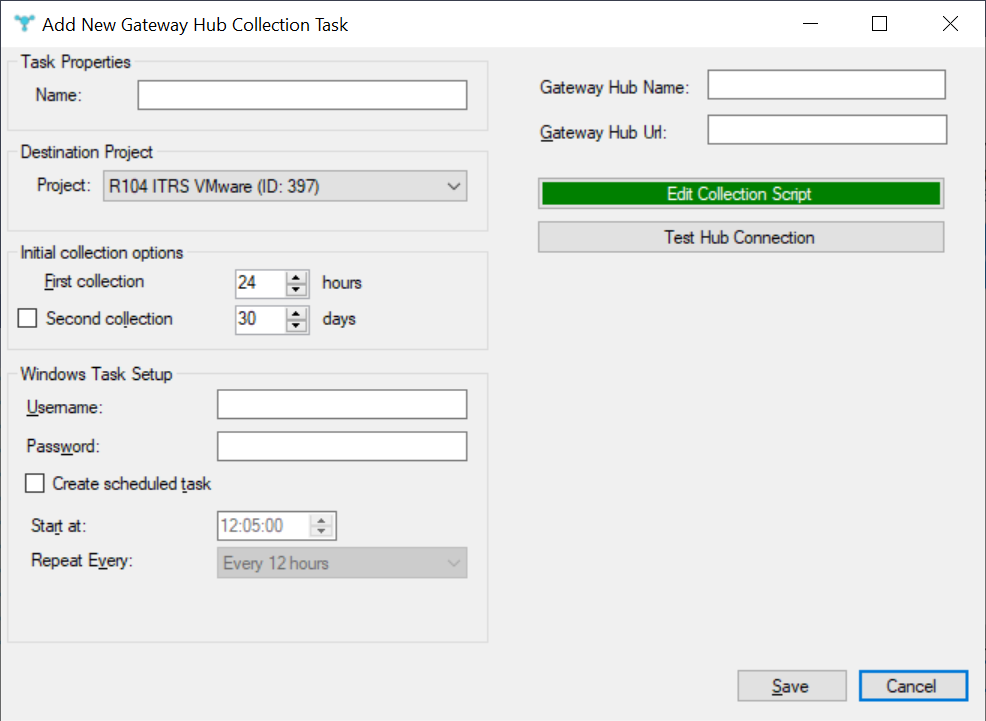
Tarea de colección de Gateway Hub Copied
La tarea de colección de Gateway Hub recopila datos de las tablas auxiliares de Geneos Capacity Planner. Para usar tareas de este tipo de colección, primero se deben configurar las tablas auxiliares en Gateway Hub. Para más información, vea Crear tablas de base de datos. Para más información, contacte a su representante de cuenta de ITRS.
Además de las propiedades genéricas de la tarea, el editor de tareas de Gateway Hub requiere lo siguiente:
- Nombre de Gateway Hub — un nombre para identificar la conexión de Gateway Hub en archivos de registro.
- URL de Gateway Hub — la URL de la conexión de Gateway Hub. Esto debería incluir el prefijo
https://y el número de puerto, por ejemplohttps://MiGatewayHub.com:8080.
La conexión se puede probar con el botón Test Hub Connection. Esto intentará una conexión y desconexión, pero no intentará recuperar ningún dato.
Script de colección Copied
The collection script is specifically configured to collect all the information required by , Capacity Planner and it is not recommended that it be altered.
If there is a requirement to edit the collection script, click Edit Collection Script. For more information, see Collection script editor.
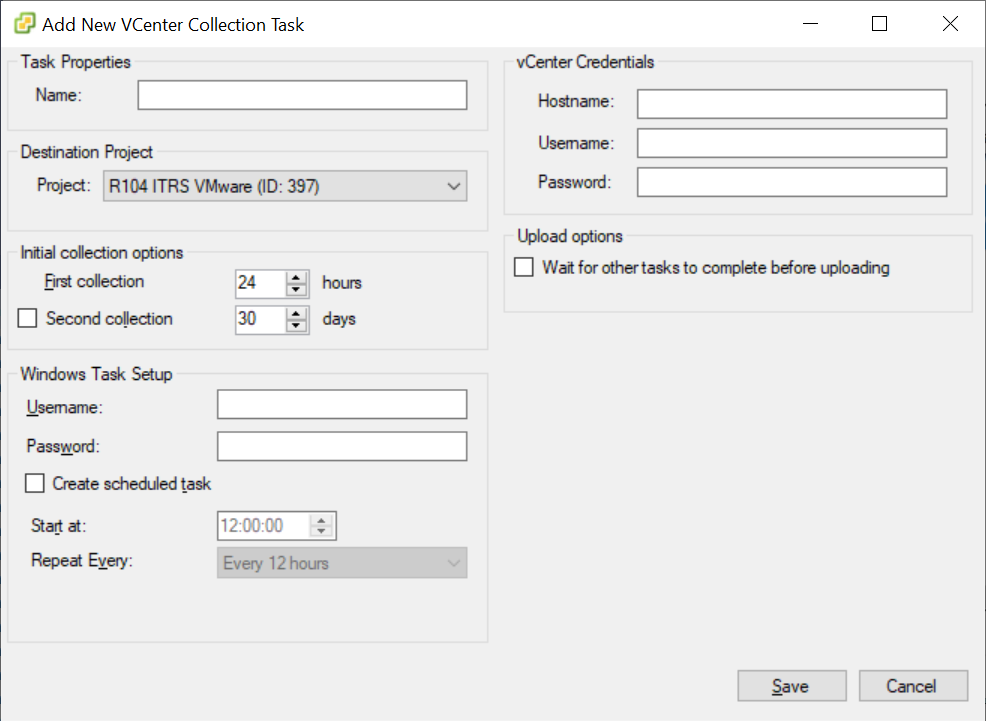
Tarea de colección de vCenter Copied
Además de las propiedades genéricas de la tarea, el editor de tareas de vCenter requiere lo siguiente:
| Propiedad | Descripción |
|---|---|
| Nombre de host | El nombre del servidor que aloja la instancia de vCenter. |
| Nombre de usuario | El nombre de usuario para la instancia de vCenter. |
| Contraseña | La contraseña para la instancia de vCenter. |
| Esperar a que otras tareas completen | Esta opción permite que una tarea de colección de vCenter se coordine con otras tareas de colección de vCenter que están apuntando a diferentes servidores. Si se han creado múltiples tareas de colección de vCenter con esta opción seleccionada, ninguna de ellas subirá resultados hasta que todas hayan terminado de recolectar datos. |
Cuando haga clic en Save, el diálogo se cierra y se realiza una prueba de conexión.
Una vez completado esto, se ejecutará una verificación para asegurar que la conexión de extremo a extremo desde el recolector a vCenter y luego a Capacity Planner esté completamente establecida. Si hay algún problema con el acceso y las credenciales, se le notificará en este punto.
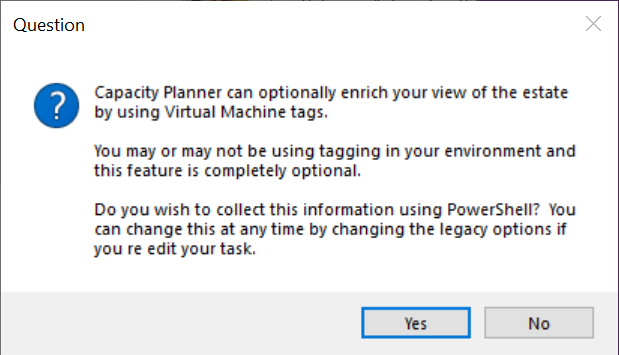
Algunos entornos hacen uso de etiquetas de Máquina Virtual para registrar detalles de aplicación, operativos o administrativos. Estas etiquetas no pueden extraerse a través de la API y requieren el uso de scripts de PowerShell dedicados que se incluyen con el Data Collector. Si desea recuperar estos, por favor responda Yes cuando se le pregunte:
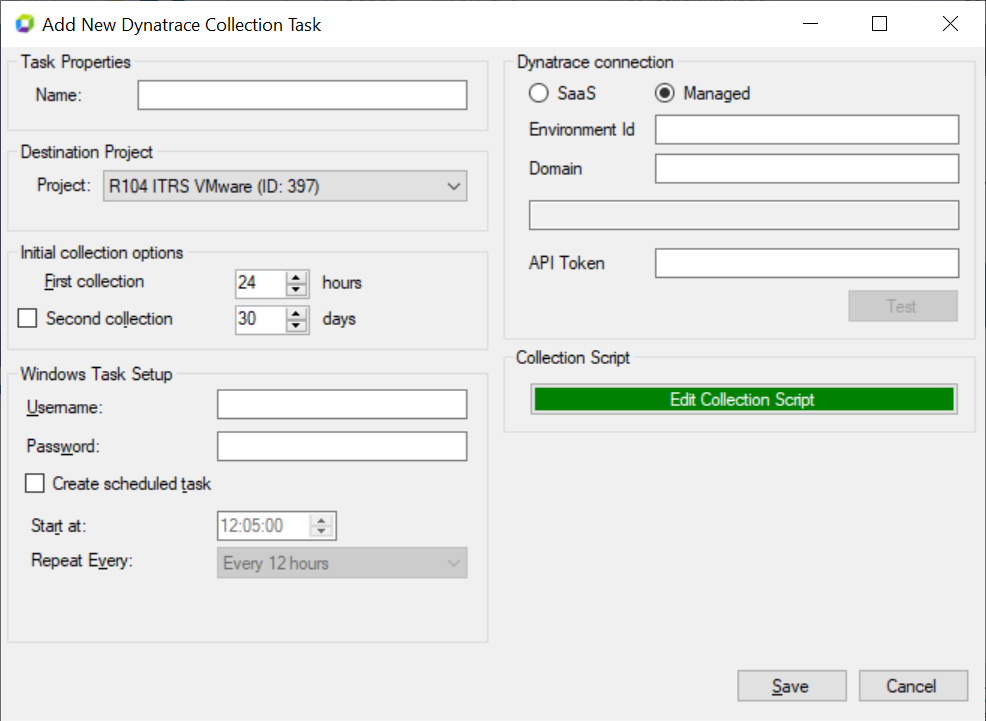
Tarea de colección de Dynatrace Copied
Además de las propiedades genéricas de la tarea, el editor de tareas de Dynatrace requiere lo siguiente:
| Propiedad | Descripción |
|---|---|
| Tipo de conexión |
|
| ID de ambiente | El ID de ambiente proporcionado por Dynatrace. |
| Dominio | Para servicios gestionados, el dominio en el que se aloja el servicio. |
| Token de API | El Token de API proporcionado por Dynatrace. |
Una vez que se hayan ingresado el tipo de conexión, el ID de ambiente y el dominio, se mostrará la URL objetivo para su verificación.
La conexión se puede probar usando el botón Test.
Script de colección Copied
The collection script is specifically configured to collect all the information required by , Capacity Planner and it is not recommended that it be altered.
If there is a requirement to edit the collection script, click Edit Collection Script. For more information, see Collection script editor.