Kluster
Ett kluster är en logisk samling av servrar och lagring som tillåter delning av resurser för en gemensam samling av virtuella maskiner samtidigt som hög tillgänglighet och lastbalansering säkerställs. I standardvyn för Baseline visas kluster som en av de förvalda aktiva grupperingarna i solburstvisningen.
The Clusters panel provides a summary of all clusters visible in the current active Baseline View . It shows the number of redundant hosts in a cluster, as well as the number of reference workloads that can be added to this cluster before the redundancy policy is breached or before the cluster reaches full saturation.
Visa klusterdetaljer Copied
Detaljer om kluster, såsom headroom eller policyer för hög tillgänglighet, kan nås från panelen Clusters som är placerad till höger om solbursten. Panelen visar en lista över alla kluster som för närvarande är synliga i solbursten.
Klicka på Options ![]() för klustret för att se ytterligare åtgärder:
för klustret för att se ytterligare åtgärder:
- Headroom — visar alla detaljer om headroom för det valda klustret.
- Alternativt kan du högerklicka på ett kluster direkt i solbursten och sedan välja Headroom för att se detaljerna. För mer information, se Headroom.
- Go to — zoomar omedelbart in på det valda klustret och visar detaljer enbart för detta kluster.
- Locate — markerar klustret i solbursten.
Policyer för hög tillgänglighet (HA) i kluster Copied
I din IT-infrastruktur kan du vilja säkerställa att ett antal enheter inom ett kluster är redundanta. Detta innebär att om dessa enheter fallerar finns det fortfarande kapacitet i ett kluster för att säkerställa fortsatt drift av maskinerna i det klustret.
Redundans uttrycks normalt i formen N+x, där x är antalet backupkomponenter som krävs.
I fallet med virtualiseringskluster är N antalet enheter som behövs för att adekvat stödja efterfrågan inom klustret, och x avser antalet ytterligare värdar. Därför, när ett kluster har en policy för hög tillgänglighet av N+2, kan det motstå fel hos 2 värdar och fortfarande ha tillräcklig kapacitet för att stödja den sammanlagda arbetsbelastningen för alla virtuella maskiner i det klustret.
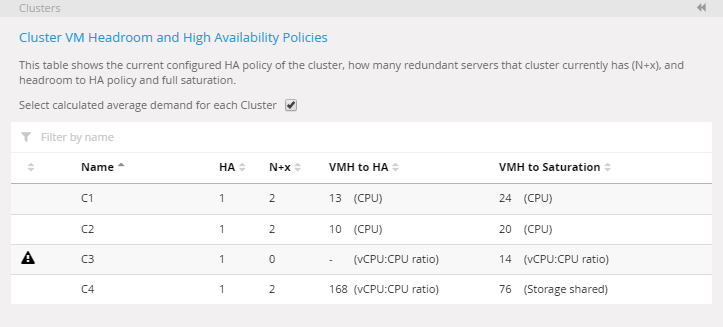
Panelen Clusters visar en tabell som visar följande information och beräkningar för varje kluster som för närvarande är synligt i solbursten:
- Policy breach warning
 — den första kolumnen i listan används för att indikera om ett kluster bryter mot HA-policy. Om det gör det visas en varningsikon.
— den första kolumnen i listan används för att indikera om ett kluster bryter mot HA-policy. Om det gör det visas en varningsikon. - HA — den nuvarande konfigurerade policyen för hög tillgänglighet för varje kluster. Ett värde av
1indikerar att klustret förväntas ha en HA-policy av N+1, vilket innebär att det måste finnas minst en redundant server. - N+x — den högsta nivån av redundans som för närvarande är möjlig för det klustret med tanke på den grundläggande resursanvändningsprofilen. Om det finns 3 eller flera redundanta servrar i klustret kommer värdet att presenteras som
3+.
Standardvärdet är inställt på1och kan ändras genom att kontakta din kontorepresentant. - VMH to HA — antalet referensarbetsbelastningar som kan läggas till i detta kluster innan redundanspolicyn bryts. Detta baseras på de valda beräkningsmetrikerna som konfigurerats med hjälp av VM-headroompanelen. För mer information, se Headroom.
- VMH to saturation — antalet referensarbetsbelastningar som kan läggas till i detta kluster innan full mättnad uppnås. Som standard anses mättnad vara full kapacitet minus den operativa reserven. För CPU är standardreserven 20% och för aktivt minne är det 40%.
Beräkna genomsnittlig efterfrågan för kluster Copied
Som standard använder tabellen för klusterheadroom den globala headroomreferensen för att bestämma redundans, headroom till N+x-kapacitet, och full kapacitet. Dock kan vissa kluster ha arbetsbelastningar som avviker betydligt från genomsnittet (till exempel ett kluster med SQL-servermaskiner). I detta fall kan användningen av en global genomsnittsmaskin som referens överdriva kapaciteten för det klustret.
För mer information om hur referensen beräknas, se Referensarbetsbelastning.
Du kan välja att använda ett beräknat genomsnitt per kluster. För att göra detta, följ dessa steg:
- I panelen Clusters, välj kryssrutan Select calculated average demand for each Cluster.
- Klicka på Apply changes. Knappen visas när du gör ändringar i panelen.
Efter en kort beräkning uppdateras tabellen för att visa headroom och redundanssiffror med hjälp av ett beräknat genomsnitt per kluster.
Att ändra beräkningarna från den globala referensen till genomsnittlig efterfrågan för kluster resulterar i att headroomsiffran som visas i panelen Clusters skiljer sig från headroomsiffran i solbursten. För att få dessa siffror att framstå på ett konsekvent sätt, följ dessa steg:
- Högerklicka på ett kluster i solbursten.
- Från dialogrutan, välj Workloads och sedan Calculate average.
- Välj kryssrutan Set this template as the reference used for headroom calculations check.
Siffrorna för det valda klustret matchar nu.
Exempel Copied
Bilden nedan visar klustertabellen med hjälp av global headroomreferens:
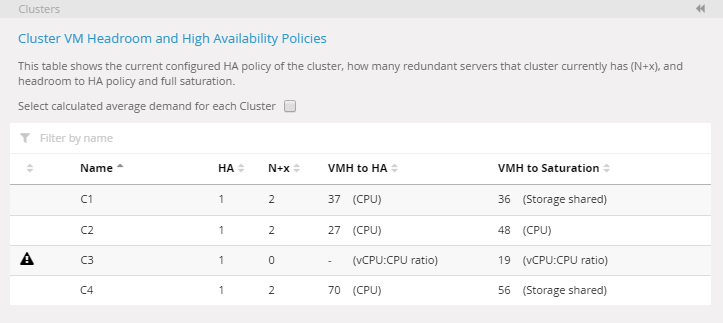
Klustertabell med användning av beräknat genomsnitt per kluster. Headroomsiffrorna har ändrats därefter.