Clusters
Un cluster es una colección lógica de servidores y almacenamiento que permite compartir recursos para una colección común de máquinas virtuales asegurando al mismo tiempo una alta disponibilidad y equilibrio de carga. En la Vista de Línea de Base predeterminada, los clusters se muestran como uno de los agrupamientos activos por defecto en el sunburst.
The Clusters panel provides a summary of all clusters visible in the current active Baseline View . It shows the number of redundant hosts in a cluster, as well as the number of reference workloads that can be added to this cluster before the redundancy policy is breached or before the cluster reaches full saturation.
Mostrar detalles del cluster Copied
Los detalles sobre los clusters, como el headroom o las políticas de alta disponibilidad, se pueden acceder desde el panel Clusters ubicado a la derecha del sunburst. El panel muestra la lista de todos los clusters actualmente visibles en el sunburst.
Haz clic en Options ![]() del cluster para ver acciones adicionales:
del cluster para ver acciones adicionales:
- Headroom — muestra todos los detalles del headroom para el cluster seleccionado.
- Alternativamente, puedes hacer clic derecho en un cluster directamente en el sunburst, y luego seleccionar Headroom para ver los detalles. Para más información, consulta Headroom.
- Go to — hace zoom inmediatamente en el cluster seleccionado y muestra detalles solo para este cluster.
- Locate — resalta el cluster en el sunburst.
Políticas de alta disponibilidad (HA) de clusters Copied
En tu infraestructura de TI, es posible que quieras asegurar que un número de dispositivos dentro de un cluster sean redundantes. Esto significa que si estos dispositivos fallan, todavía hay capacidad en un cluster para asegurar la operación continua de las máquinas en ese cluster.
La redundancia se expresa normalmente en la forma de N+x, donde x es el número de componentes de respaldo requeridos.
En el caso de los clusters de virtualización, N es el número de dispositivos necesarios para soportar adecuadamente la demanda dentro del cluster, y x se refiere al número de hosts adicionales. Por lo tanto, cuando un cluster tiene una política de alta disponibilidad de N+2, puede resistir la falla de 2 hosts y aún tener suficiente capacidad para soportar la carga de trabajo agregada de todas las máquinas virtuales en ese cluster.
El panel Clusters muestra una tabla que muestra la siguiente información y cálculos para cada cluster que está actualmente visible en el sunburst:
- Policy breach warning
 — la primera columna de la lista se utiliza para indicar si un cluster está violando la política de HA. Si es así, se muestra un icono de advertencia.
— la primera columna de la lista se utiliza para indicar si un cluster está violando la política de HA. Si es así, se muestra un icono de advertencia. - HA — la política de alta disponibilidad configurada actualmente de cada cluster. Un valor de
1indica que se espera que el cluster tenga una política de HA de N+1, lo que significa que debe haber al menos un servidor redundante. - N+x — el nivel más alto de redundancia actualmente alcanzable para ese cluster dado el perfil de utilización de recursos de línea base. Si hay 3 o más servidores redundantes en el cluster, el valor se presentará como
3+. El valor predeterminado se establece en1y se puede cambiar contactando a tu representante de cuenta. - VMH to HA — el número de cargas de trabajo de referencia que se pueden agregar a este cluster antes de que se viole la política de redundancia. Esto se basa en las métricas de cálculo seleccionadas configuradas usando el panel de headroom de VM. Para más información, consulta Headroom.
- VMH to saturation — el número de cargas de trabajo de referencia que se pueden agregar a este cluster antes de alcanzar la saturación completa. Por defecto, la saturación se considera como la capacidad total menos la reserva operacional. Para la CPU, la reserva predeterminada es del 20% y para la memoria activa es del 40%.
Calcular la demanda promedio para el cluster Copied
Por defecto, la tabla de headroom del cluster utiliza la referencia de headroom global para determinar la redundancia, el headroom a la capacidad N+x y la capacidad total. Sin embargo, algunos clusters pueden tener cargas de trabajo que se desvían significativamente del promedio (por ejemplo, un cluster de máquinas de servidor SQL). En este caso, usar una máquina promedio global como referencia puede sobreestimar la capacidad para ese cluster.
Para más información sobre cómo se calcula la referencia, consulta Carga de trabajo de referencia.
Puedes elegir usar un promedio calculado por cluster. Para hacer esto, sigue estos pasos:
- En el panel Clusters, selecciona la casilla de verificación Select calculated average demand for each Cluster.
- Haz clic en Apply changes. El botón aparece cuando haces cambios en el panel.
Después de un breve cálculo, la tabla se actualiza para mostrar las cifras de headroom y redundancia usando un promedio calculado por cluster.
Cambiar los cálculos de la referencia global a la demanda promedio por cluster resulta en que la cifra de headroom que se muestra en el panel Clusters sea diferente de la cifra de headroom en el sunburst. Para hacer que estos números aparezcan de manera consistente, sigue estos pasos:
- Haz clic derecho en un cluster en el sunburst.
- Desde el cuadro de diálogo, selecciona Workloads y luego Calculate average.
- Selecciona la casilla de verificación Set this template as the reference used for headroom calculations check.
Los números para el cluster elegido ahora coinciden.
Ejemplo Copied
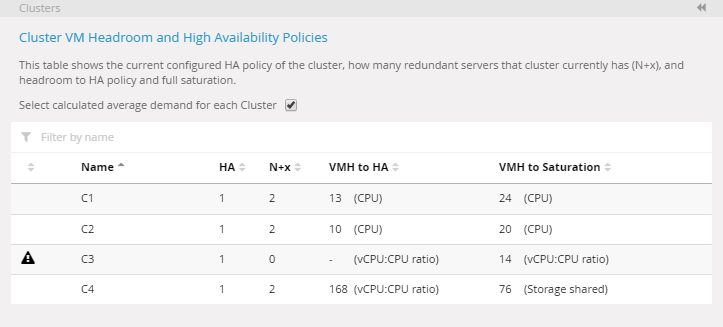
La imagen a continuación muestra la tabla del cluster usando la referencia de headroom global:
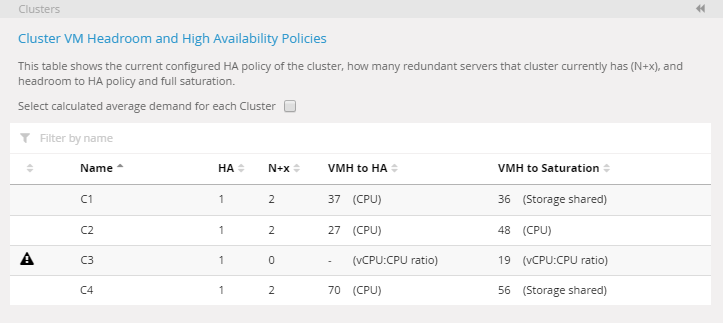
Tabla del cluster usando el promedio calculado por cluster. Las cifras de headroom han cambiado en consecuencia.